Chunk computing en PHP
vom 28. August 2024
La présentation liée à l'article :
Le chunking est une technique polyvalente utilisée dans divers domaines, notamment la psychologie cognitive et l'informatique, pour améliorer l'efficacité, améliorer les performances et simplifier les tâches complexes. Cet article se penche sur les principes du chunking, en offrant des exemples pratiques et des aperçus sur sa mise en œuvre dans la technologie et l'apprentissage.
Pourquoi ?
Le chunking a été développé pour répondre aux limites inhérentes au traitement cognitif et à la mémoire humaine. En décomposant les informations en unités plus petites et gérables, le chunking permet un traitement mental plus efficace et un rappel plus facile. En technologie, ce concept se traduit par la gestion de grands ensembles de données ou de tâches complexes en les divisant en morceaux plus petits et plus digestes, améliorant ainsi l'efficacité du traitement et réduisant les erreurs.
Qu'est-ce que le « chunking » ?
En technologie, un « chunk » est un segment discret de données qui est transféré, traité ou stocké en tant qu'unité. Les chunks sont utilisés dans divers systèmes, notamment les bases de données, les communications réseau et les opérations de stockage, pour décomposer de grands ensembles de données en morceaux plus petits et plus gérables. Cette approche simplifie la gestion des données, améliore la vitesse de traitement et améliore les performances globales du système.
Principaux points à retenir
Le concept de découpage, lorsqu'il est compris comme une méthode de décomposition d'informations complexes en parties plus simples, peut être résumé comme suit :
- Le découpage permet une compréhension, un traitement et une mémorisation plus faciles des informations complexes.
- Il est essentiel pour améliorer l'apprentissage et la rétention de la mémoire en organisant les informations de manière logique.
- Le découpage est une technique polyvalente applicable dans divers domaines, de la psychologie cognitive au traitement des données en technologie.
Si « morceau » fait référence à autre chose, comme un personnage d'un film ou d'un livre, ou à un concept dans un contexte différent, j'aurais besoin de ces informations pour fournir des conclusions plus spécifiques.
Importance
Le concept de « morceau » en technologie est crucial car il sous-tend des stratégies efficaces de gestion et de traitement des données. En divisant des fichiers ou des ensembles de données volumineux en morceaux plus petits et gérables, les systèmes peuvent optimiser l'utilisation de la mémoire, accélérer le traitement des données et améliorer la récupération des erreurs. En réseau, le découpage facilite la transmission de données plus fluide et plus fiable, tandis qu'en programmation, il facilite le développement de code modulaire, rendant la maintenance et le débogage plus faciles à gérer.
Explication
Les découpages font partie intégrante de divers processus technologiques, servant de méthode fondamentale pour traiter, stocker et transférer efficacement des données. Dans le stockage de données, les découpages permettent la distribution de fichiers volumineux sur différents emplacements, optimisant les temps de récupération et protégeant les données. La programmation bénéficie du découpage en permettant des structures de code modulaires, qui simplifient le débogage et améliorent l'efficacité du développement. Dans les communications réseau, le découpage garantit que les gros paquets de données sont divisés en morceaux gérables, réduisant ainsi le risque de perte de données pendant la transmission. Le thème récurrent dans ces applications est que le découpage rend les tâches complexes de traitement des données plus efficaces et plus fiables.
Exemples
-
Fractionnement de fichiers : dans les opérations sur fichiers, le terme « découpage » désigne un bloc de données transféré d'un emplacement à un autre. Les services de partage de fichiers tels que BitTorrent décomposent les fichiers volumineux en morceaux plus petits, ou « morceaux », pour faciliter une transmission de données plus rapide et plus efficace.
-
Streaming vidéo : sur des plateformes comme YouTube ou Netflix, les vidéos sont divisées en petits « morceaux ». Cela permet une diffusion plus fluide car chaque morceau est chargé et lu pendant que le suivant est en cours de chargement, évitant ainsi de devoir charger la vidéo entière avant le début de la lecture.
-
Traitement des Big Data : dans le Big Data, les ensembles de données sont souvent traités en « morceaux » pour plus d'efficacité. Par exemple, Apache Hadoop utilise une méthode de « découpage » pour rendre l'analyse de données à grande échelle plus gérable. Les données sont divisées en fragments plus petits ou « morceaux », chacun pouvant être traité en parallèle sur différentes machines d'un réseau pour accélérer le temps de traitement.
-
Formation sur le modèle d'IA : dans l'IA, les données sont divisées en lots plus petits pendant la formation, ce qui permet des mises à jour fréquentes, un apprentissage plus rapide et une gestion efficace d'ensembles de données volumineux.
En psychologie
En psychologie, le découpage est le processus de regroupement d'éléments d'information individuels en unités plus grandes et cohérentes ou « morceaux », qui peuvent être facilement rappelés comme un seul élément. Par exemple, un maître d'échecs reconnaît et rappelle les modèles sur un échiquier comme des morceaux de configurations significatives plutôt que des pièces individuelles. Cette capacité à découper efficacement les informations est ce qui distingue souvent les experts des novices dans n'importe quel domaine.
Comment le « chunking » peut-il m'aider à apprendre le développement logiciel ?
Dans le développement logiciel, le chunking pourrait être utilisé pour apprendre divers concepts, tels que :
-
Un modèle de conception comme le décorateur.
-
Une technique telle que l'utilisation de curl et de SSH pour identifier un problème de connectivité.
-
Un framework/une technologie comme Amazon ECS.
Une fois maîtrisé, vous n'avez plus besoin de réfléchir aux étapes individuelles. Diagnostiquer un problème devient assez simple, car vous savez instinctivement où chercher.
Dans la gestion de la mémoire
Les systèmes logiciels modernes typiques allouent dynamiquement de la mémoire à partir de structures appelées tas. Des appels sont effectués vers des routines de gestion de tas pour allouer et libérer de la mémoire. La gestion des tas implique un certain temps de calcul et peut poser des problèmes de performances. Le découpage en morceaux fait référence à des stratégies visant à améliorer les performances en utilisant des connaissances spécifiques d'une situation pour regrouper les demandes d'allocation de mémoire associées. Par exemple, si l'on sait qu'un certain type d'objet sera généralement requis par groupe de huit, au lieu d'allouer et de libérer chaque objet individuellement (ce qui nécessite seize appels au gestionnaire de tas), on pourrait allouer et libérer un tableau de huit objets, réduisant ainsi le nombre d'appels à deux.
Voyons ce que cela signifie et comment le découpage peut aider à optimiser les performances.
-
Allocation dynamique : dans de nombreuses applications logicielles, la mémoire n'est pas toujours allouée au démarrage. Au lieu de cela, elle est allouée de manière dynamique au fur et à mesure de l'exécution du programme, en fonction des besoins de l'application à un moment donné. Cette mémoire dynamique provient d'une zone appelée le tas. Cependant, la gestion de ce tas peut prendre du temps car chaque fois que le programme a besoin de plus de mémoire, il doit effectuer un appel au tas pour allouer ou libérer de l'espace.
-
Impact sur les performances : plus votre programme doit effectuer ces appels de gestion de tas souvent, plus votre système peut devenir lent. Chaque appel pour allouer ou libérer de la mémoire prend du temps et de la puissance de traitement, ce qui peut s'accumuler, surtout si votre programme effectue ces appels fréquemment.
-
Stratégie de segmentation : c'est là que la segmentation entre en jeu comme une stratégie intelligente pour réduire l'impact sur les performances. Au lieu d'effectuer un appel de gestion du tas chaque fois que vous devez allouer ou libérer de la mémoire pour un seul objet, la segmentation vous permet de regrouper les allocations de mémoire associées.
-
Exemple : Imaginez que vous avez un programme qui doit souvent créer et détruire plusieurs objets, disons 8 à la fois. Au lieu d'allouer et de libérer de la mémoire pour chaque objet individuellement (ce qui nécessiterait 16 appels de tas distincts, 8 pour allouer et 8 pour libérer), vous pouvez allouer de la mémoire pour les 8 objets en une seule fois et la libérer en une seule fois. Cela réduit le nombre d'appels de gestion du tas de 16 à seulement 2, réduisant considérablement la surcharge et accélérant votre programme.
En appliquant la segmentation dans la gestion de la mémoire, votre programme peut gérer la mémoire plus efficacement, réduisant les délais et améliorant les performances globales du système. Cette approche est particulièrement bénéfique dans les applications hautes performances où chaque milliseconde compte.
Itération traditionnelle
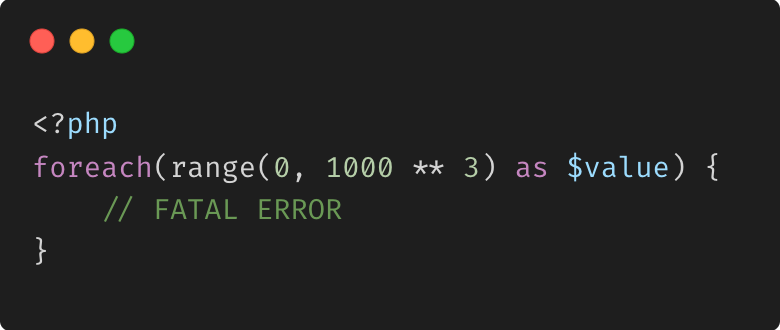
Lors du traitement de grands ensembles de données, l'itération traditionnelle peut entraîner des problèmes de consommation de mémoire importants :
- Utilisation élevée de la mémoire :
Le chargement simultané de quantités massives de données dans la mémoire peut consommer une grande partie de la RAM disponible.
Si l'ensemble de données dépasse la mémoire disponible, cela peut entraîner un ralentissement considérable du système, voire un blocage.
- Dégradation des performances :
Les systèmes peuvent recourir à l'utilisation de l'espace d'échange (en utilisant le stockage sur disque comme mémoire supplémentaire), qui est beaucoup plus lent que la RAM.
- Problèmes d'évolutivité :
Les applications qui fonctionnent bien avec de petits ensembles de données peuvent ne pas évoluer correctement à mesure que les données augmentent. Limite la capacité à traiter efficacement les données en temps réel ou en streaming.
array_chunk : fractionnement d'un index simple Tableau

Sortie

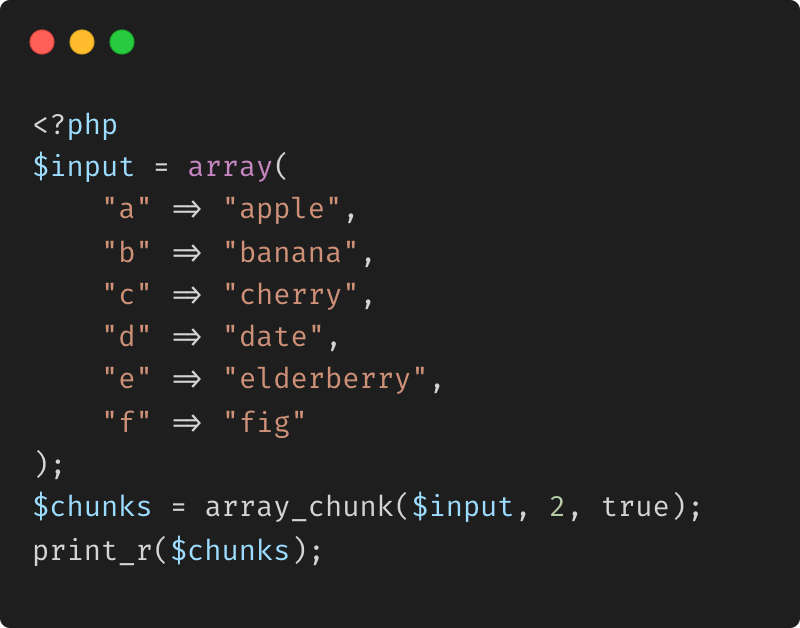
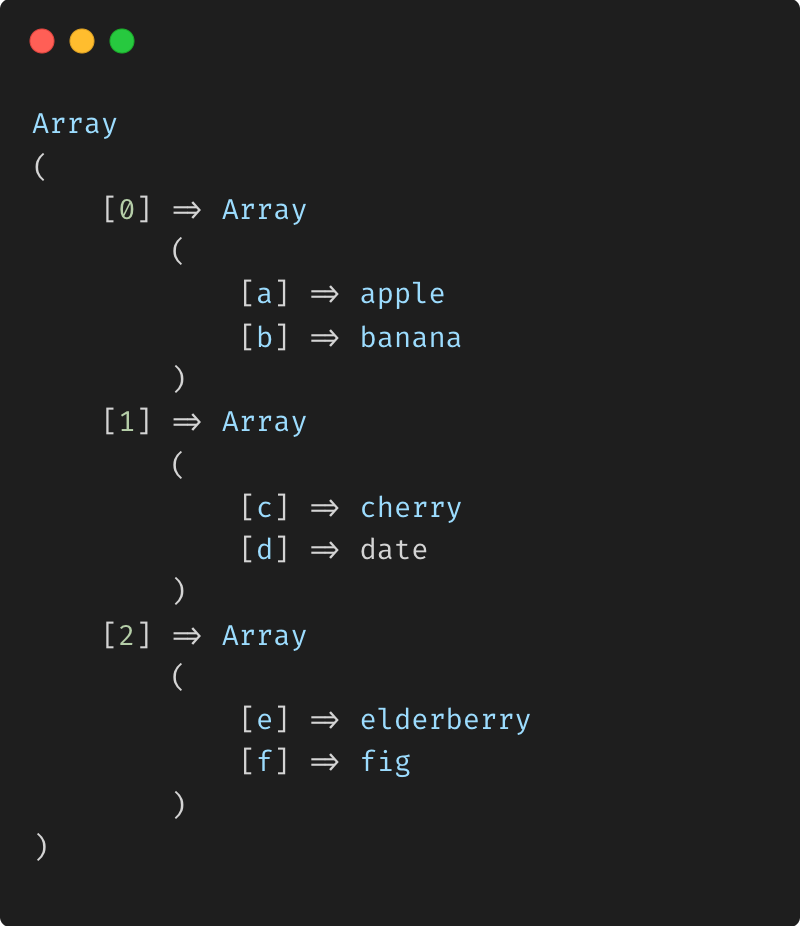
array_chunk : Fractionnement d'un tableau associatif avec préservation Clés
Résultat
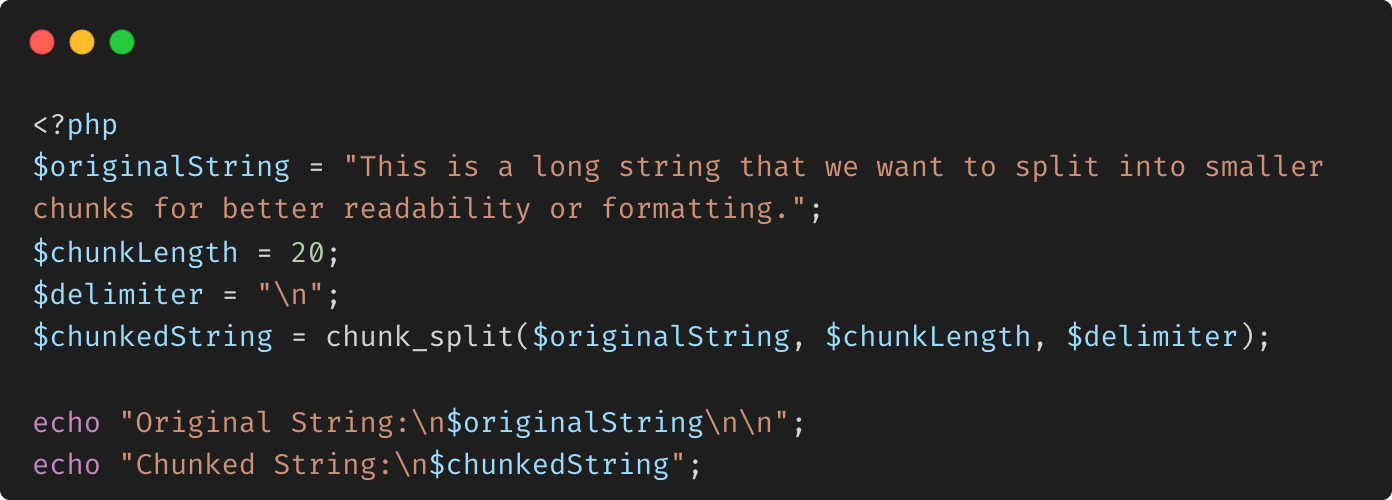
chunk_split
La fonction chunk_split() en PHP est utilisée pour diviser une chaîne en morceaux plus petits et éventuellement ajouter un délimiteur (comme une nouvelle ligne ou un espace) après chaque morceau. Cela peut être utile pour formater la sortie, par exemple lorsque vous devez diviser une longue chaîne en parties gérables.
Sortie

Threaded::chunk
La méthode Threaded::chunk() fait partie de l'extension pthreads en PHP, qui est utilisée pour le multithreading. Elle vous permet de diviser les données stockées dans un objet Threaded en morceaux plus petits et plus faciles à gérer, qui peuvent ensuite être traités indépendamment, souvent en parallèle par plusieurs threads. La méthode chunk() divise un objet Threaded en morceaux plus petits, cette méthode est particulièrement utile dans la programmation concurrente lorsqu'il s'agit de grands ensembles de données qui doivent être traités en plusieurs parties.
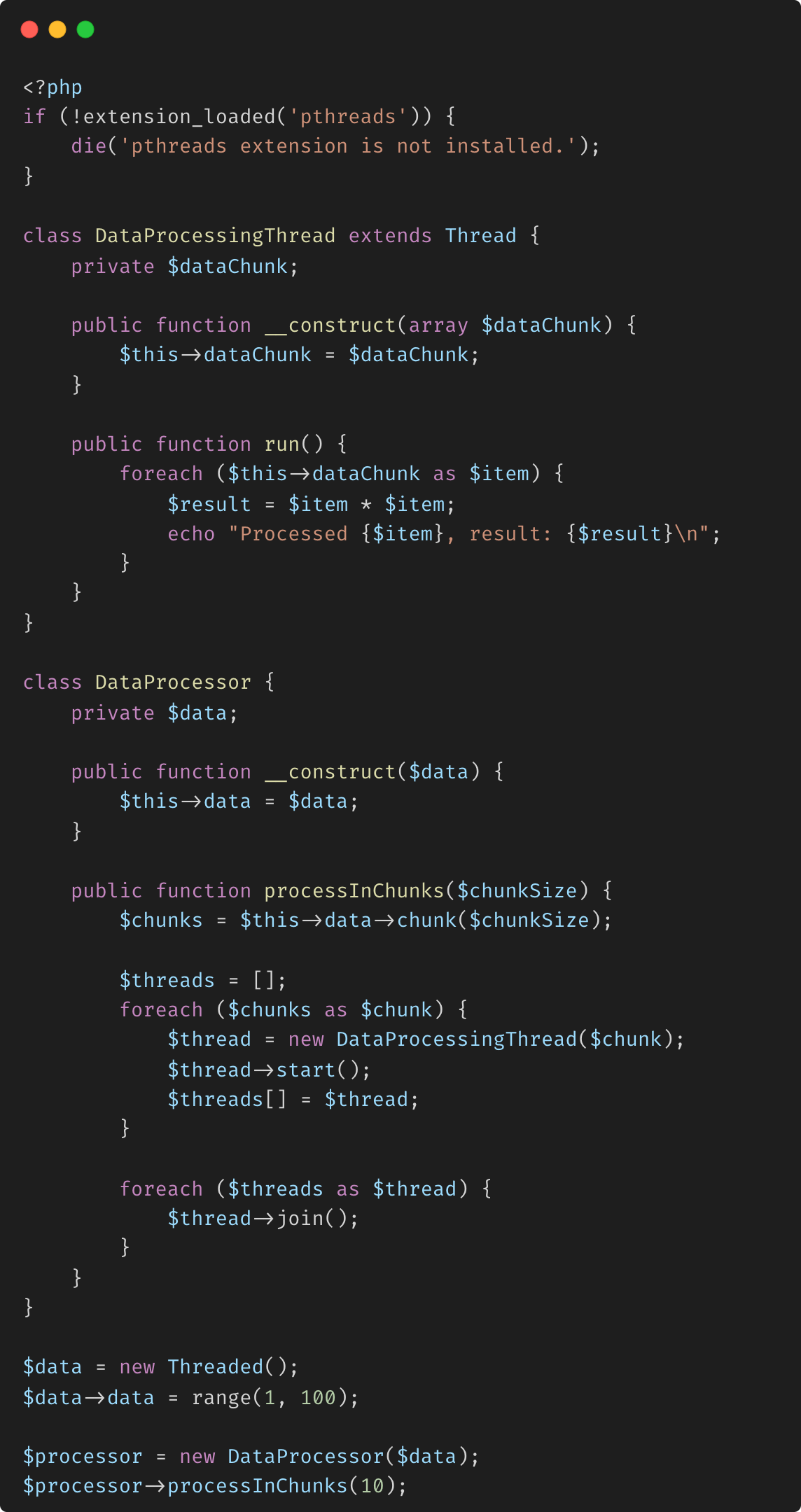
Sortie

-
Fractionnement des données en morceaux : la méthode chunk divise le contenu d'un objet Threaded en morceaux plus petits d'une taille spécifiée. Chaque morceau est un tableau contenant un sous-ensemble des éléments de l'objet Threaded d'origine. En divisant les données en morceaux, vous pouvez gérer et traiter efficacement de grands ensembles de données en parallèle, améliorant ainsi les performances et réduisant la complexité de la gestion de données volumineuses au sein d'un seul thread.
-
Classe DataProcessor : la classe DataProcessor gère la logique de fractionnement de l'ensemble de données en morceaux et de traitement de chaque morceau dans un thread distinct.
-
Concurrence et parallélisme : dans un environnement multithread, chaque fragment peut être traité par un thread distinct. Ce traitement parallèle permet une exécution plus rapide des tâches, en particulier lorsqu'il s'agit d'opérations liées au processeur, telles que Mathematical calculs ou opérations liées aux E/S, comme la lecture et l'écriture sur le disque ou la communication réseau. Plusieurs threads s'exécutent simultanément, chacun traitant un bloc de données différent. La méthode join garantit que le thread principal attend que tous les threads de traitement soient terminés avant de terminer l'exécution.
-
Création d'objets threadés : un objet threadé est créé contenant un grand ensemble de données d'entiers (de 1 à 100).
-
Création et exécution de threads : pour chaque bloc, un DataProcessingThread est créé et démarré. Ce thread traite chaque élément du bloc (par exemple, en mettant le nombre au carré) et imprime le résultat.
-
Efficacité de la mémoire : en traitant les données par blocs, vous évitez de charger l'ensemble de données en mémoire en une seule fois. Cela est particulièrement bénéfique lorsque vous travaillez avec de grands ensembles de données, car cela réduit la consommation de mémoire et minimise le risque d'erreurs de dépassement de mémoire.
fread
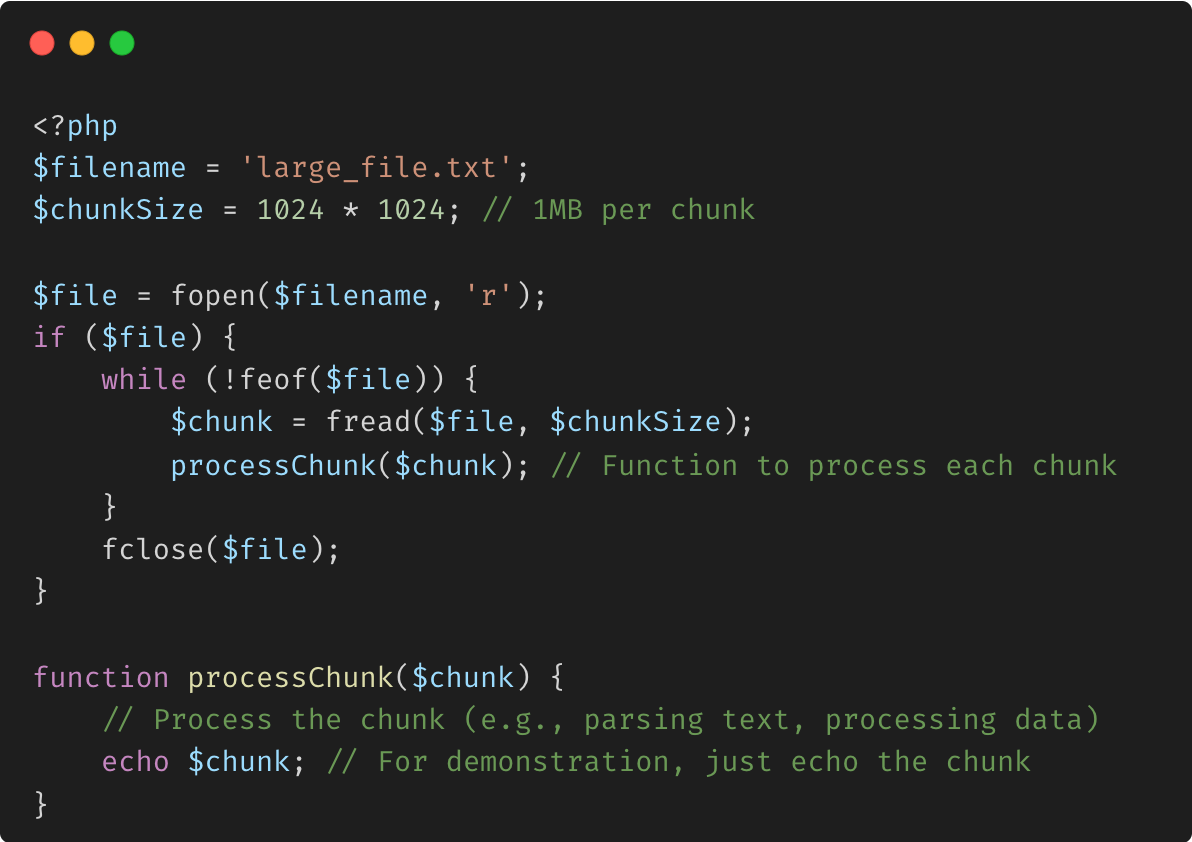
Avantages :
Utilisation efficace de la mémoire : seule une petite partie du fichier est chargée en mémoire à la fois. Gestion des fichiers volumineux : vous pouvez travailler avec des fichiers bien plus volumineux que la mémoire disponible.
Utilisation de SplFileObject pour une gestion efficace des fichiers
La classe SplFileObject fournit une méthode orientée objet pour gérer les fichiers et peut être particulièrement utile pour lire des fichiers volumineux ligne par ligne sans charger l'intégralité du fichier en mémoire.
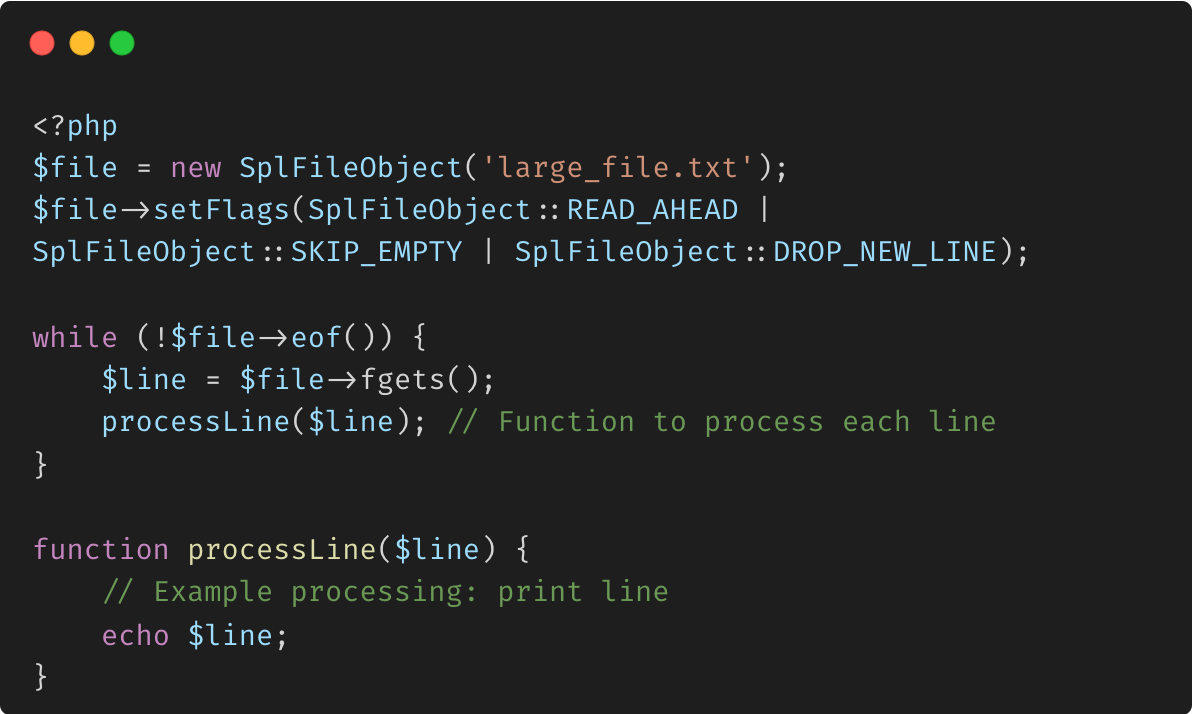
Avantages :
Traitement ligne par ligne : une seule ligne est chargée en mémoire à la fois, ce qui la rend adaptée aux fichiers très volumineux. Flexibilité : SplFileObject fournit divers indicateurs et méthodes pour une gestion efficace des fichiers.
Fonctions de gestion de la mémoire
PHP fournit plusieurs fonctions qui vous permettent de surveiller et de gérer l'utilisation de la mémoire dans vos scripts. Ces fonctions peuvent vous aider à écrire du code économe en mémoire, en particulier dans les processus ou scripts de longue duréequi gèrent des données volumineuses.
memory_get_usage() Renvoie la quantité de mémoire, en octets, actuellement utilisée par votre script PHP.

memory_get_peak_usage() Renvoie l'utilisation maximale de la mémoire (quantité de mémoire la plus élevée utilisée) pendant l'exécution de votre script.
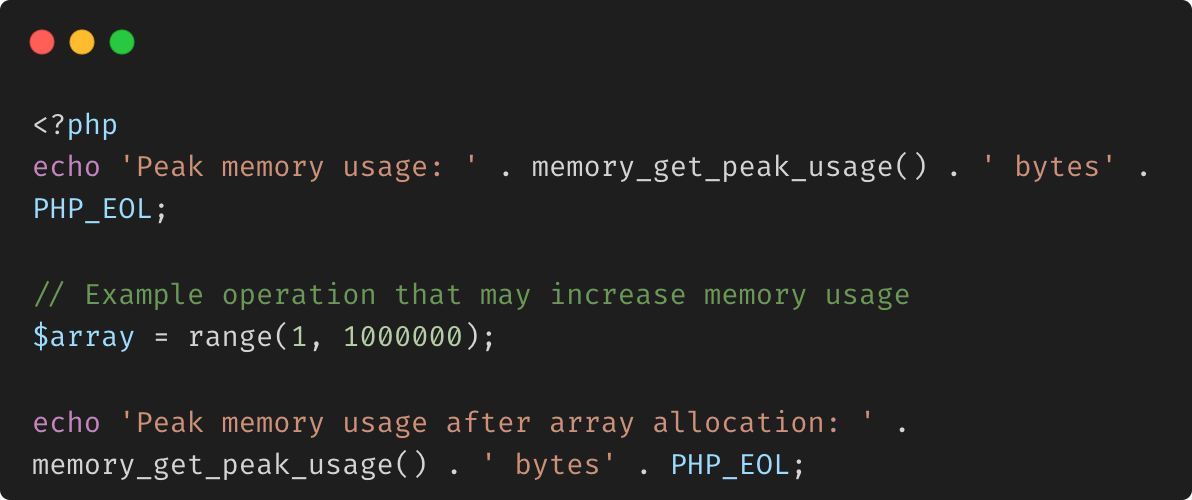
gc_collect_cycles() Cette fonction force la collecte de tous les cycles de garbage existants. Le garbage collector de PHP nettoie les références circulaires en mémoire, mais parfois une intervention manuelle peut aider dans les scripts de longue durée.
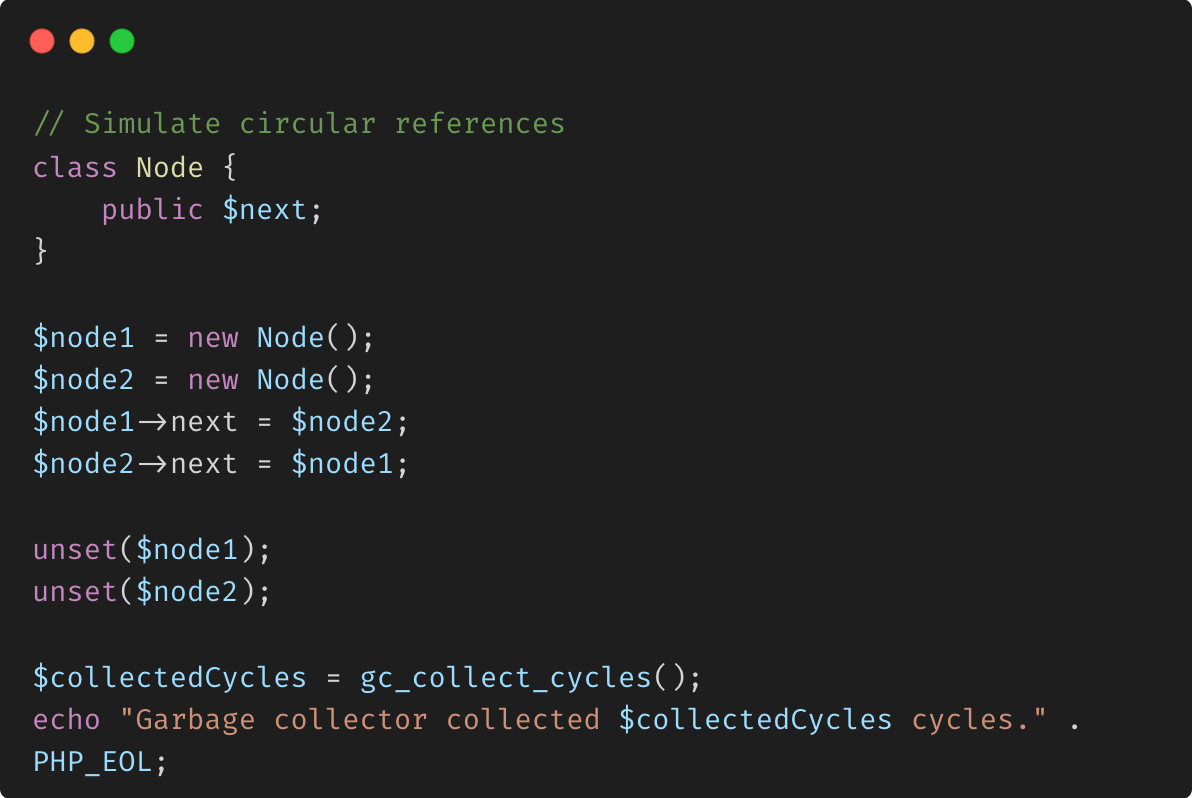
Utilisation des générateurs
Les générateurs PHP vous permettent d'itérer sur les données sans charger l'ensemble de données en mémoire en une seule fois. Ceci est particulièrement utile lorsque vous travaillez avec des sources de données ou des flux volumineux.

Avantages :
Efficacité de la mémoire : un seul élément est traité à la fois, ce qui réduit considérablement l'utilisation de la mémoire par rapport au chargement de l'ensemble de données en une seule fois. Adapté aux grands ensembles de données : idéal pour les scénarios où vous devez traiter de grands ensembles de données ou des flux sans épuiser la mémoire.
unset() et libération de mémoire
En PHP, unset() est utilisé pour détruire une variable et libérer la mémoire qui lui est associée. Cela peut être particulièrement utile dans les scripts de longue durée où la mémoire doit être gérée activement.
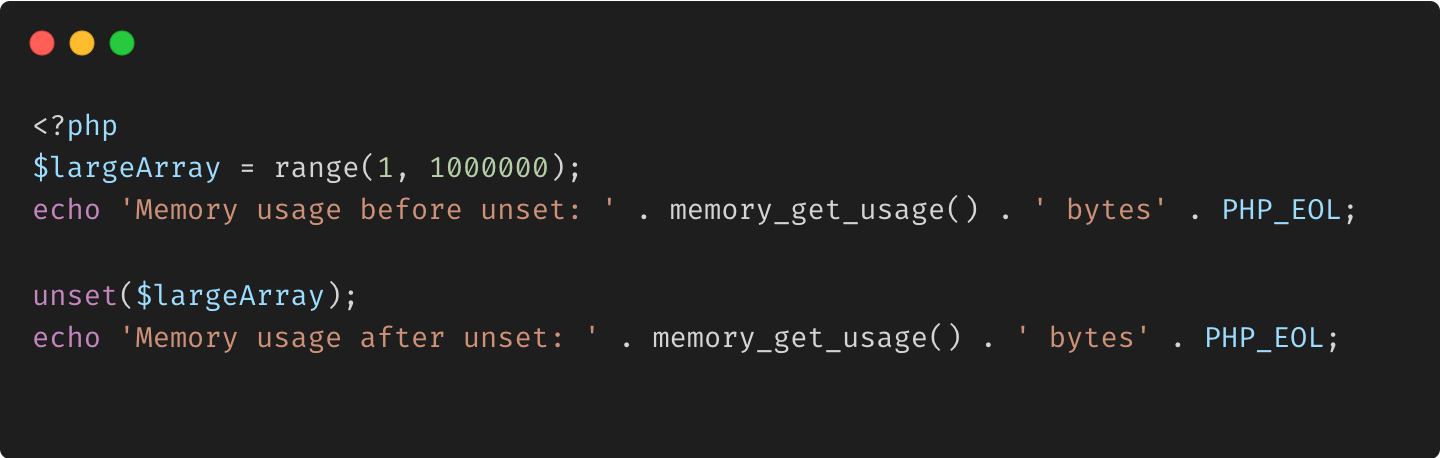
Avantages :
Récupération de mémoire : gérez activement l'utilisation de la mémoire en libérant de la mémoire lorsque les variables ne sont plus nécessaires. Empêche les fuites de mémoire : aide à éviter les fuites de mémoire dans les scripts de longue durée.
loophp/collection : Chunk
La classe Chunk de la bibliothèque Loophp Collection est conçue pour diviser une collection itérable en morceaux plus petits et de taille fixe. La classe implémente une opération immuable qui renvoie un générateur, qui produit des tableaux représentant des morceaux de la collection d'origine. Elle permet des tailles de morceaux dynamiques en utilisant un itérateur cyclique, ce qui permet d'avoir des tailles variables pour différents morceaux au sein de la même opération. Cette approche est particulièrement utile lors de la gestion de grands ensembles de données, permettant un traitement plus efficace en les divisant en morceaux gérables.
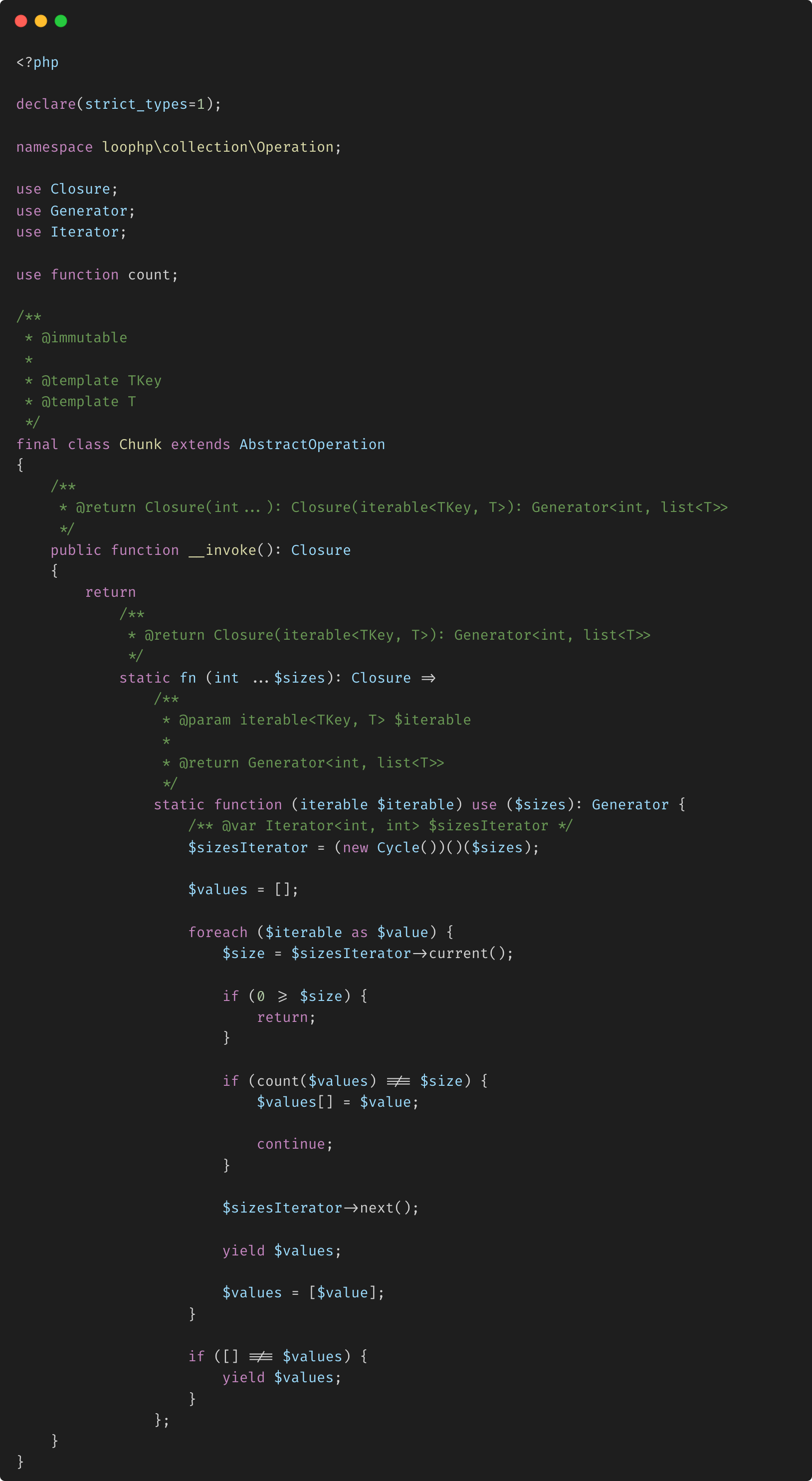
La classe Chunk dans ce code PHP est conçue pour diviser un itérable en morceaux de tailles variables. Elle renvoie une fermeture qui prend une série d'entiers représentant les tailles de morceaux et un itérable. Elle utilise un itérateur cyclique (Cycle) pour appliquer ces tailles de manière répétée pendant qu'elle traite l'itérable. Si une taille de morceau est atteinte, elle cède ce morceau et passe à la taille suivante. Ce processus continue jusqu'à ce que l'itérable entier soit consommé.
Exemple de cas d'utilisation Supposons que vous ayez une liste d'éléments et que vous souhaitiez les diviser en morceaux avec des tailles qui se répètent dans un cycle, comme [2, 3, 2] :

Sortie

Cet exemple illustre comment l'itérable est décomposé en morceaux de tailles 2, 3, 2, en répétant le motif selon les besoins.
Dans la transmission de messages HTTP
Le découpage en blocs est une fonctionnalité spécifique du protocole HTTP 1.1. Ici, la signification est opposée à celle utilisée dans la gestion de la mémoire. Il fait référence à la capacité de décomposer de gros messages en « blocs » plus petits et plus faciles à gérer. Il a été introduit dans HTTP/1.1, qui a été documenté pour la première fois dans la RFC 2068, publiée en janvier 1997. Le codage de transfert en blocs permet d'envoyer des données dans une série de blocs afin qu'un serveur puisse commencer à envoyer des données avant que la longueur complète du contenu ne soit connue. Il s'agissait d'une amélioration significative par rapport à HTTP/1.0, où la longueur du contenu devait être connue et envoyée avant que des données puissent être transmises.
Qu'est-ce que le codage de transfert en blocs ?
Le codage de transfert en blocs est un mécanisme de transfert de données dans HTTP/1.1 qui permet à un serveur d'envoyer une réponse en blocs générés dynamiquement sans avoir besoin de connaître la longueur finale du contenu avant la transmission. Cela est particulièrement utile pour diffuser des fichiers volumineux ou des données en temps réel, où la taille totale du contenu peut ne pas être connue au début de la réponse.
Pourquoi utiliser le codage de transfert en bloc ?
Dans le protocole HTTP/1.0 antérieur, le serveur devait connaître la longueur totale du corps de la réponse avant de pouvoir commencer à envoyer des données. Cette exigence posait des problèmes, en particulier lorsqu'il s'agissait de contenu volumineux généré de manière dynamique. HTTP/1.1 a introduit le codage de transfert en bloc pour répondre à ces défis. Avec le codage de transfert en bloc, le serveur peut commencer à transmettre des parties de la réponse immédiatement, ce qui améliore les performances perçues et réduit la latence pour l'utilisateur final.
Comment fonctionne le codage de transfert en bloc
Dans le codage de transfert en bloc, le serveur envoie le corps de la réponse sous forme d'une série de blocs. Chaque bloc commence par la taille du bloc (en hexadécimal), suivi des données réelles et d'un CRLF (Carriage Return Line Feed) de fin. La fin du message est indiquée par un bloc d'une taille de « 0 ».
Exemple : 4\r\n Wiki\r\n 5\r\n pedia\r\n E\r\n en\r\n morceaux.\r\n 0\r\n \r\n
4\r\nWiki\r\n- Ce morceau fait 4 octets de long et contient la chaîne « Wiki ».5\r\npedia\r\n- Ce morceau fait 5 octets de long et contient la chaîne « pedia ».E\r\n en\r\nchunks.\r\n- Ce morceau fait 14 octets de long (E en hexadécimal) et contient la chaîne « en morceaux ».0\r\n\r\n- Il s'agit du dernier morceau, indiquant la fin du message.
Comment les clients gèrent le codage de transfert par blocs
Lorsqu'un client (par exemple, un navigateur Web) reçoit une réponse par blocs, il lit chaque bloc en fonction de la taille fournie, le traite et continue la lecture jusqu'à ce qu'il rencontre un bloc de taille « 0 », signalant la fin des données. Ce processus permet aux clients de commencer à traiter les données reçues sans attendre la réponse complète, améliorant ainsi les performances perçues.
Réponse par blocs et meilleures performances perçues
Revenons en arrière et examinons pourquoi nous voudrions nous assurer que notre serveur envoie des blocs le plus tôt possible. Dans son livre « High Performance Browser Networking », Ilya Grigorik explique pourquoi l'utilisation du vidage HTTP peut améliorer les performances.
Le document HTML est analysé de manière incrémentielle par le navigateur, ce qui signifie que le serveur peut et doit vider le balisage du document disponible aussi souvent que possible. Cela permet au client de découvrir et de commencer à récupérer les ressources critiques dès que possible.
Cela est particulièrement vrai pour la partie
du document HTML qui déclare les feuilles de style dont la page a besoin. Plus tôt le navigateur sait quelles feuilles de style demander, plus tôt il peut les télécharger et commencer à créer le CSSOM, ce qui signifie que la première peinture se produira également plus tôt.Cas d'utilisation de l'encodage de transfert en morceaux
-
Streaming vidéo : les services de streaming vidéo comme YouTube ou Netflix utilisent l'encodage de transfert en morceaux pour envoyer des données vidéo en segments. Cette approche permet à la vidéo de commencer à jouer avant que le fichier entier ne soit téléchargé, réduisant ainsi les temps d'attente et la mise en mémoire tampon pour les utilisateurs.
-
Flux de données en temps réel : les applications qui fournissent des mises à jour de données en temps réel, telles que les résultats sportifs en direct, les données du marché financier ou les flux de médias sociaux, bénéficient de l'encodage de transfert en morceaux. Les données peuvent être envoyées au client dès qu'elles sont disponibles, ce qui garantit des mises à jour rapides sans attendre que l'ensemble des données soit compilé.
-
Téléchargements de fichiers volumineux : lorsqu'il s'agit de téléchargements de fichiers volumineux, en particulier ceux générés de manière dynamique (comme un rapport ou un fichier journal), l'encodage de transfert en morceaux permet au téléchargement de démarrer immédiatement. Cela réduit le temps d'attente des utilisateurs avant que le fichier ne commence à se télécharger.
-
Événements envoyés par le serveur (SSE) : dans les événements envoyés par le serveur, où le serveur envoie en continu des mises à jour de données au client, l'encodage de transfert en bloc garantit un flux d'informations fluide et efficace, améliorant ainsi la réactivité de l'application.
Exemple de scraping Web avec l'utilisation de Symfony
Lorsque vous scrapez des sites Web qui utilisent l'encodage de transfert en bloc, la bibliothèque HTTP sous-jacente que vous utilisez doit gérer automatiquement le décodage du transfert en bloc pour vous. La plupart des bibliothèques clientes HTTP modernes prennent en charge c'est prêt à l'emploi. Voyez comment nous procédons dans Symfony.
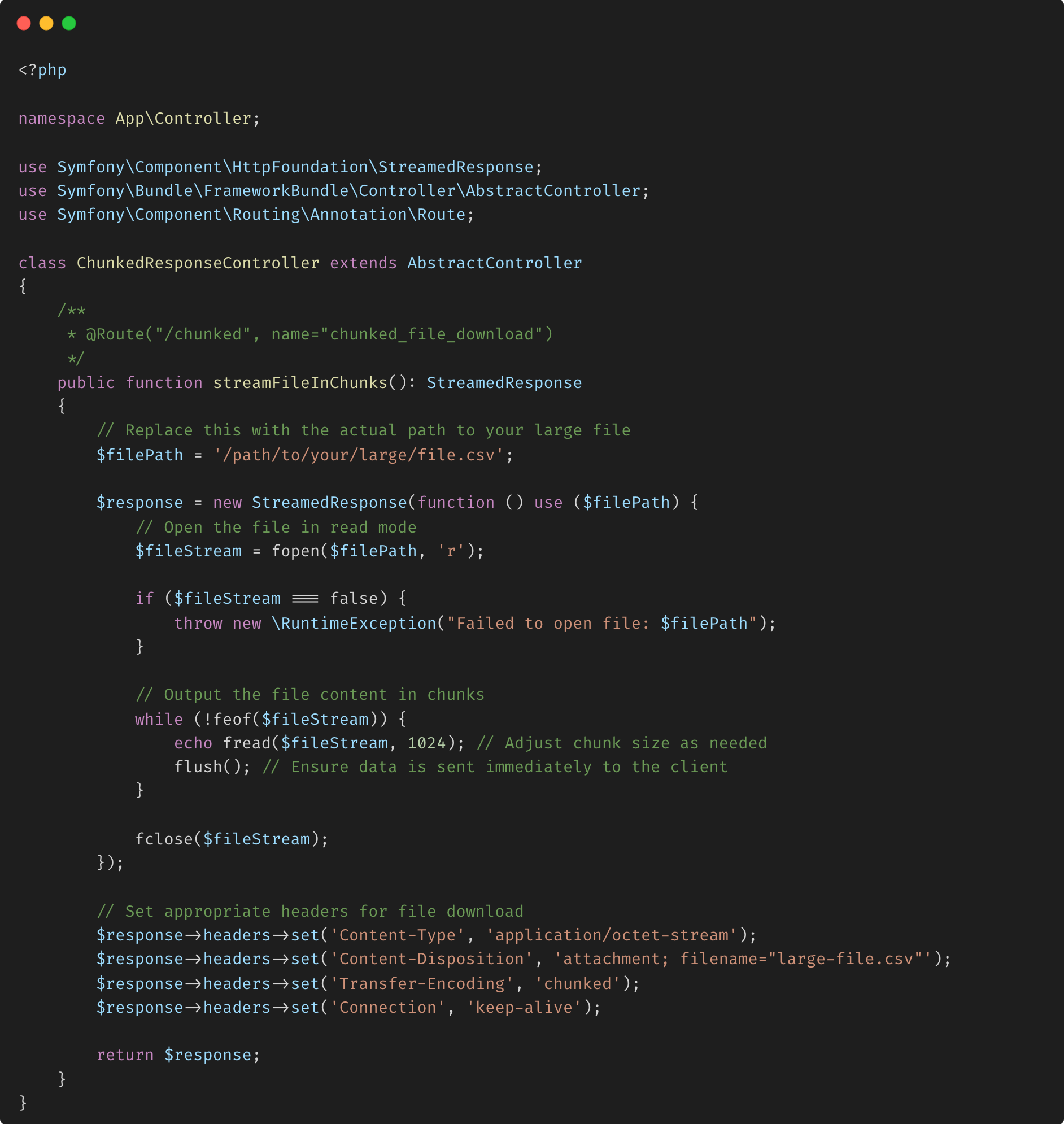
Explication :
- StreamedResponse : permet à Symfony d'envoyer le fichier en morceaux plutôt que de charger le fichier entier en mémoire.
- fread() et flush() : cette combinaison lit le fichier en morceaux de 1 Mo et envoie chaque morceau au client immédiatement, évitant ainsi une surcharge de mémoire.
- En-têtes : l'en-tête fragmenté Transfer-Encoding garantit que le client interprète correctement la réponse.
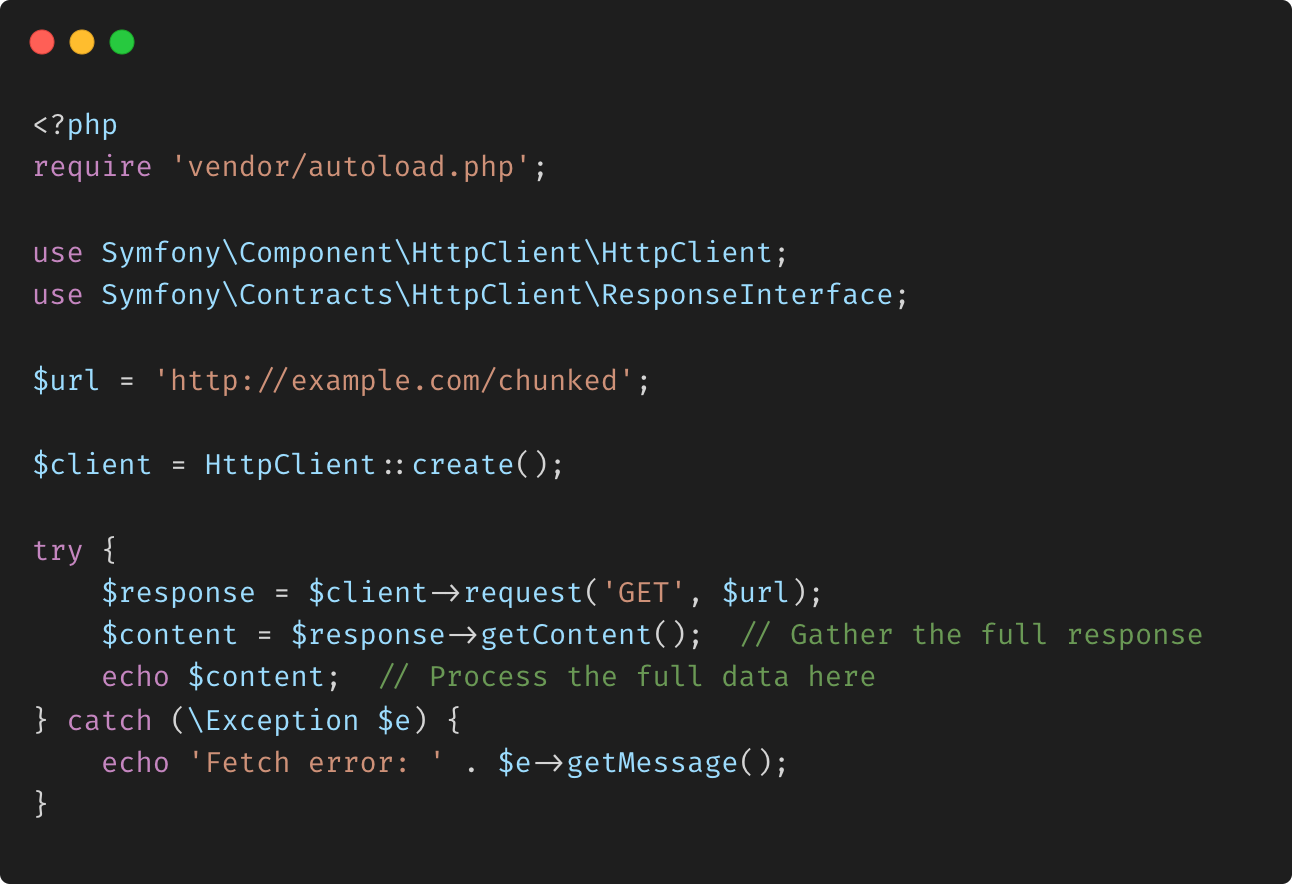
- Exemple 1 : Traiter la réponse complète :
Cette approche récupère la réponse entière en une seule fois et la traite comme une chaîne complète. La méthode getContent() est utilisée pour rassembler tous les fragments, et vous pouvez gérer les données après la réception de la réponse complète.
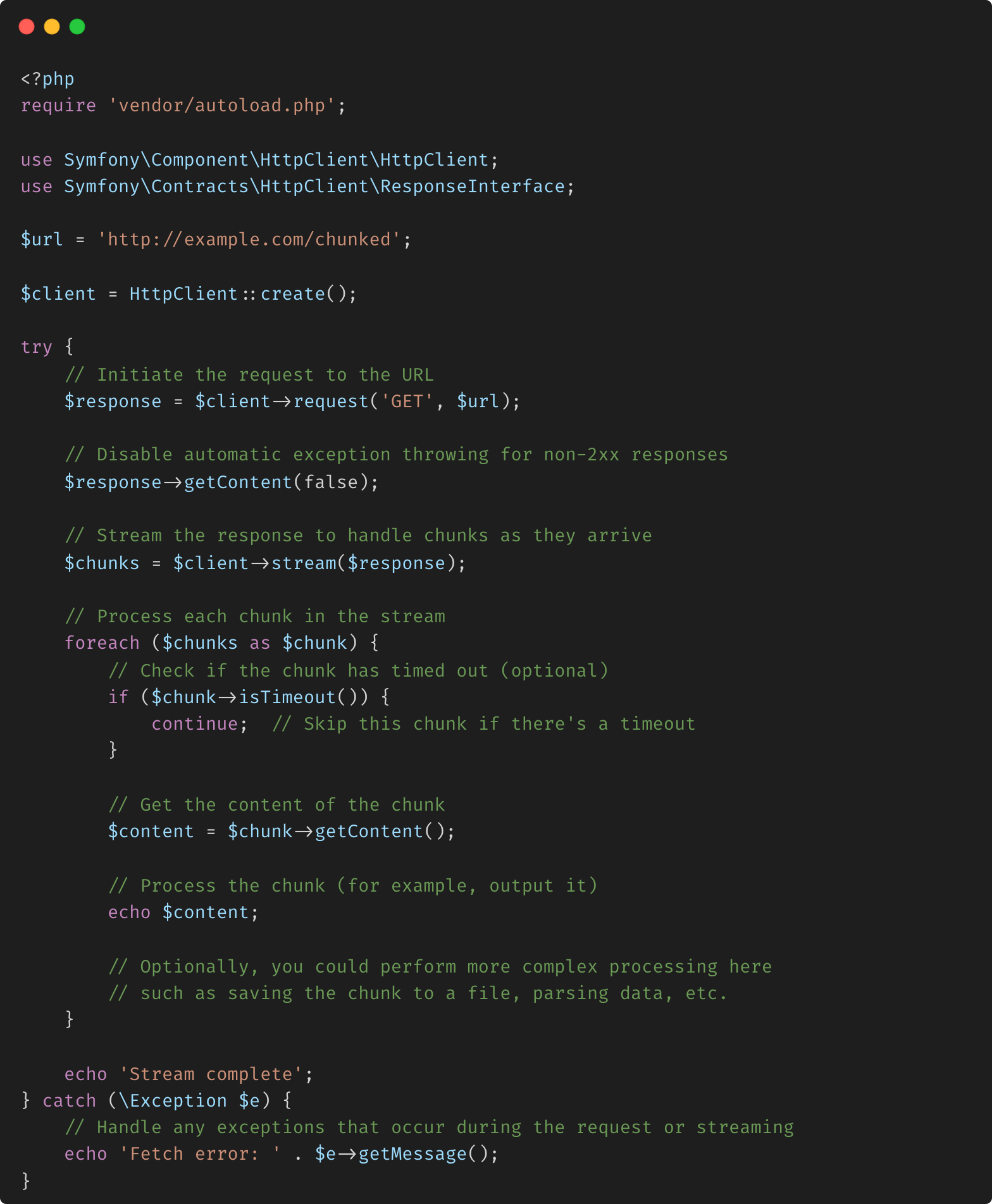
- Exemple 2 : Traiter les fragments individuellement :
Cette méthode vous permet de traiter chaque fragment de la réponse au fur et à mesure de son arrivée. En utilisant la méthode stream() et en itérant sur chaque fragment avec each(), vous pouvez gérer les données de manière incrémentielle, ce qui est utile pour les réponses volumineuses ou le traitement en temps réel.
Les deux méthodes conviennent à différents cas d'utilisation selon que vous devez gérer l'intégralité de la réponse en une seule fois ou traiter les données de manière incrémentielle au fur et à mesure de leur arrivée. Le client HTTP Symfony fournit des outils robustes pour gérer efficacement ces scénarios.
Quand utiliser l'encodage de transfert en bloc dans Symfony :
- Génération de contenu dynamique : si votre application génère des rapports ou des journaux volumineux à la volée, l'encodage de transfert en bloc vous permet de démarrer le téléchargement immédiatement.
- Environnements à mémoire limitée : dans les cas où l'utilisation de la mémoire est un problème, l'encodage de transfert en bloc réduit l'empreinte mémoire en évitant de charger des fichiers entiers en mémoire.
- Amélioration de l'expérience utilisateur : en démarrant immédiatement le transfert de données, les utilisateursbénéficiez de temps de chargement plus rapides et de temps d'attente réduits pour les téléchargements volumineux.
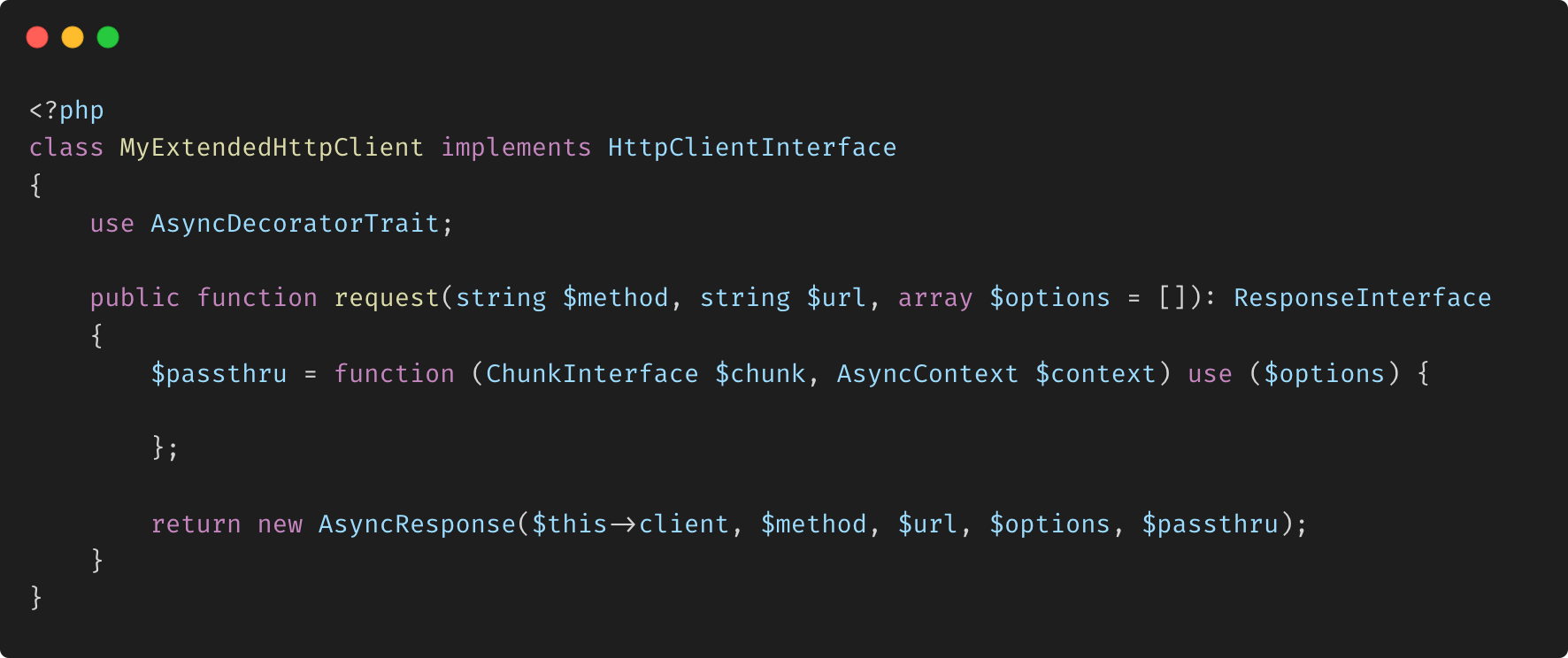
Gestion des opérations asynchrones avec AsyncDecoratorTrait dans Symfony HttpClient
Traditionnellement, les requêtes HTTP synchrones peuvent entraîner des goulots d'étranglement, où l'exécution du code est bloquée en attendant les réponses. Ce comportement bloquant peut ralentir considérablement une application, en particulier lorsqu'il s'agit de plusieurs appels d'API ou de grands ensembles de données. AsyncDecoratorTrait de Symfony offre une solution en permettant aux développeurs de gérer les réponses HTTP de manière asynchrone, sans compromettre le contrôle du flux de données.
-
Qu'est-ce que AsyncDecoratorTrait ? AsyncDecoratorTrait est une fonctionnalité du composant Symfony HttpClient qui permet la gestion asynchrone des réponses HTTP. Il permet aux développeurs d'étendre les fonctionnalités d'un client HTTP en le décorant de capacités asynchrones supplémentaires. Ce trait est particulièrement utile dans les scénarios où plusieurs requêtes HTTP doivent être gérées simultanément, ce qui permet des opérations non bloquantes et des performances d'application améliorées.
-
Comment ça marche ? Le trait AsyncDecoratorTrait fonctionne en permettant la manipulation des flux de réponses à leur arrivée, sans attendre que la réponse entière soit reçue. Cela est particulièrement utile dans les situations où un traitement immédiat des données est requis ou lorsque plusieurs requêtes HTTP dépendantes sont effectuées.
Lors de l'utilisation du trait AsyncDecoratorTrait, les données de réponse sont traitées par blocs, qui sont traités dès qu'ils sont disponibles. Cette approche garantit que l'application reste réactive et que les ressources sont utilisées efficacement. De plus, le trait fournit des mécanismes pour gérer les erreurs avec élégance, comme l'annulation d'une réponse ou la nouvelle tentative d'une requête en cas de problème.
- Applications pratiques
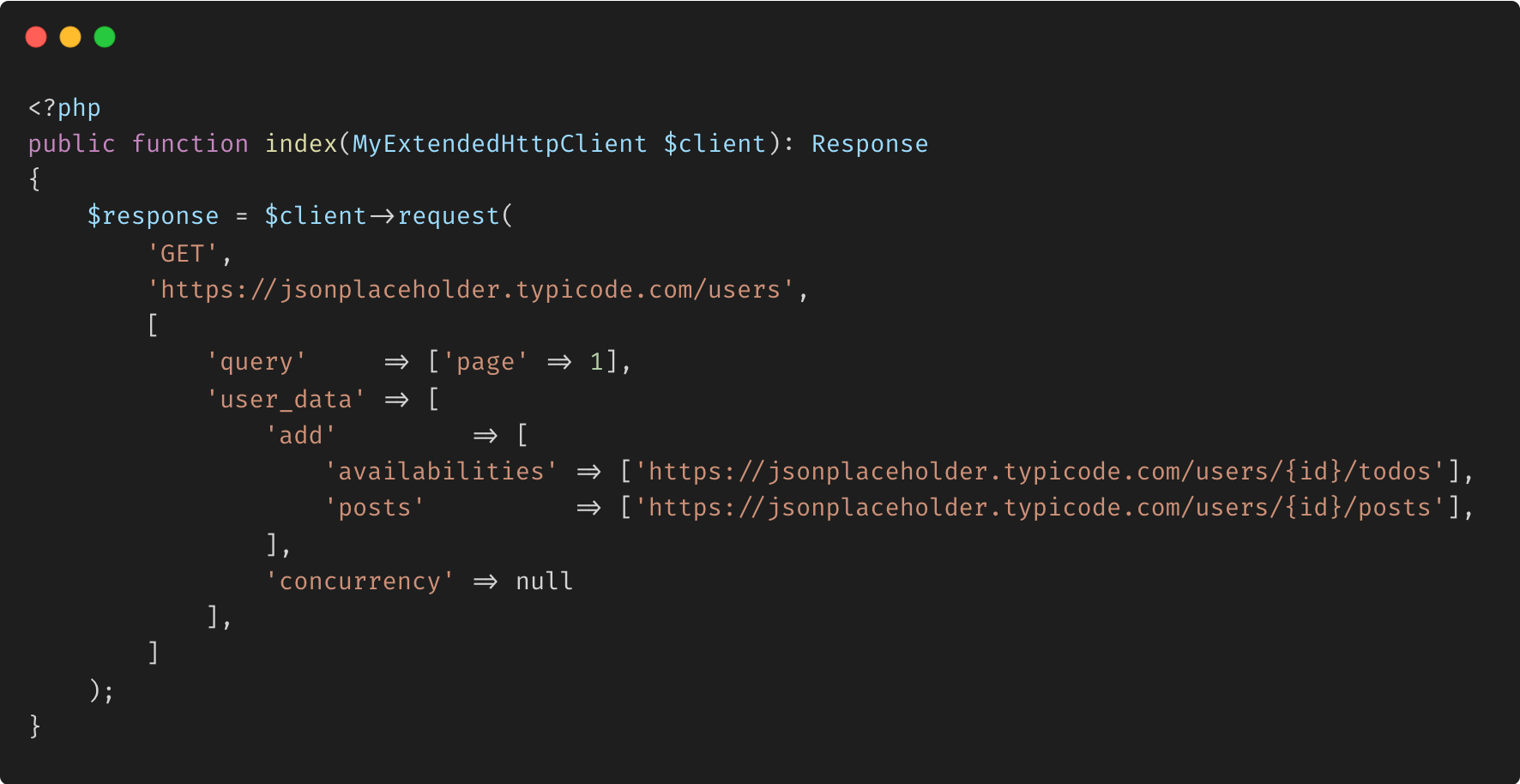
Transclusion d'API : une application pratique du trait AsyncDecoratorTrait est la transclusion d'API, où une réponse d'API principale est augmentée de données provenant d'autres API. Avec le trait AsyncDecoratorTrait, vous pouvez lancer plusieurs requêtes d'API simultanément et fusionner leurs résultats à leur arrivée. Cette approche accélère non seulement le processus, mais garantit également que l'application ne se bloque pas en attendant toutes les réponses.
Gestion des erreurs avec élégance : Un autre avantage important du trait AsyncDecoratorTrait est sa capacité à gérer les erreurs dans un contexte asynchrone. Par exemple, si une erreur 404 est rencontrée lors d'une requête, le trait vous permet d'annuler la réponse, d'émettre une nouvelle requête ou de remplacer entièrement la réponse. Cette fonctionnalité est particulièrement utile lors du traitement de données paginées ou de la recherche dans plusieurs sources où des erreurs peuvent survenir de manière sporadique.
- Exemple : gestion des requêtes HTTP asynchrones
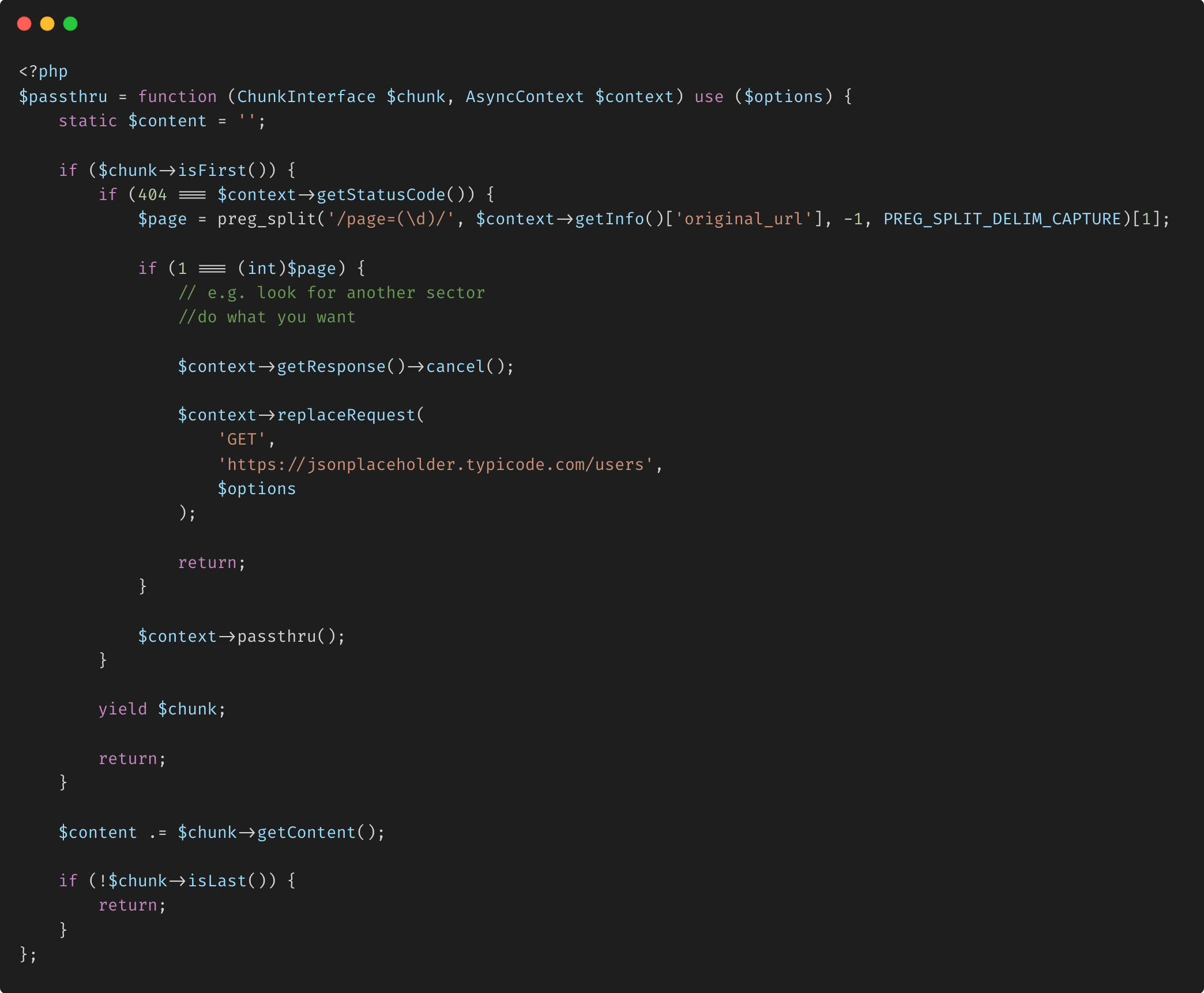
- Avantages et limites
Avantages :
Performances améliorées : en gérant les réponses de manière asynchrone, l'application peut traiter les données plus rapidement et plus efficacement, réduisant ainsi le risque de goulots d'étranglement.
Opérations non bloquantes : le trait AsyncDecoratorTrait permet des requêtes HTTP non bloquantes, garantissant que l'application peut continuer à exécuter d'autres tâches en attendant les réponses.
Gestion flexible des erreurs : le trait fournit des mécanismes robustes pour gérer les erreurs dans un contexte asynchrone, facilitant ainsi la gestion des flux de travail complexes.
Limitations :
Complexité : la gestion des flux de travail asynchrones peut introduire une complexité supplémentaire, en particulier lors du traitement de plusieurs requêtes simultanées.
Gestion des ressources : bien que cette caractéristique améliore les performances, il est important de gérer les ressources avec soin pour éviter de submerger le système avec trop de requêtes simultanées.
Streaming de données avec la mise en mémoire tampon de sortie de PHP
Les fonctions de mise en mémoire tampon de sortie de PHP peuvent être utilisées pour gérer efficacement la sortie de données par blocs, en particulier lorsque vous souhaitez envoyer des données au client progressivement. La mise en mémoire tampon de sortie peut aider à contrôler le moment où les données sont envoyées au client, ce qui permet d'obtenir des réponses par blocs.
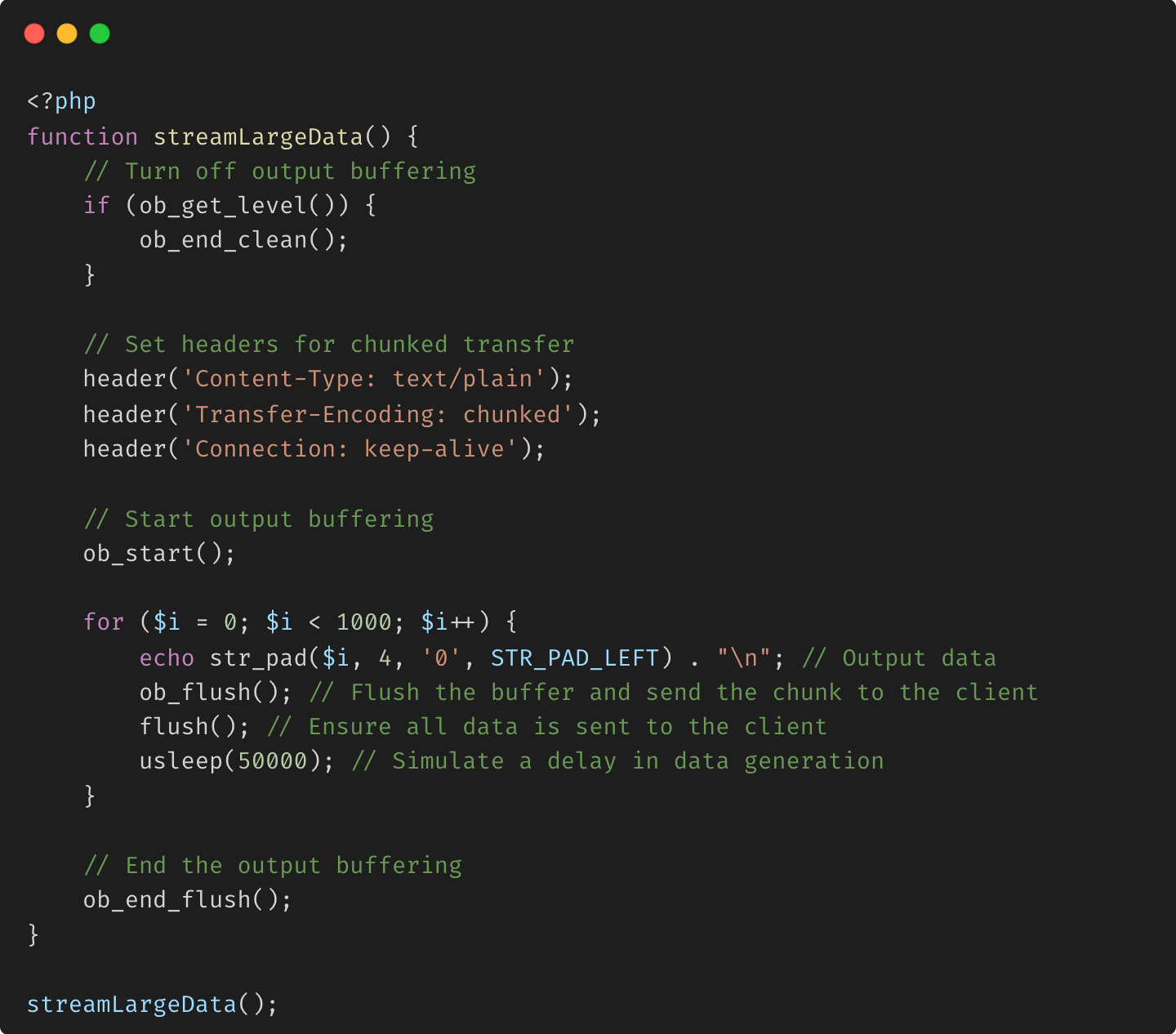
Explication :
- ob_start() : démarre la mise en mémoire tampon de sortie, vous permettant de contrôler quand la sortie est envoyée au client.
- ob_flush() et flush() : ces fonctions garantissent que le contenu actuel du tampon est envoyé immédiatement au client, ce qui permet au serveur d'envoyer des données par blocs.
- Délai simulé : la fonction usleep() introduit un délai entre les blocs, simulant un scénario réel dans lequel les données sont générées ou traitées au fil du temps.
Cas d'utilisation :
Cette méthode est utile dans les scénarios où les données sont générées ou traitées à la volée, comme lors de la diffusion de journaux, de la génération de rapports ou de la livraison de grands ensembles de données assemblés de manière dynamique.
Envoi incrémentiel de données JSON
Parfois, vous devrez peut-être envoyer de grandes structures de données JSON au client de manière incrémentielle. Cela peut être fait en utilisant un codage de transfert par blocs pour envoyer chaque partie du JSON au fur et à mesure de sa génération.
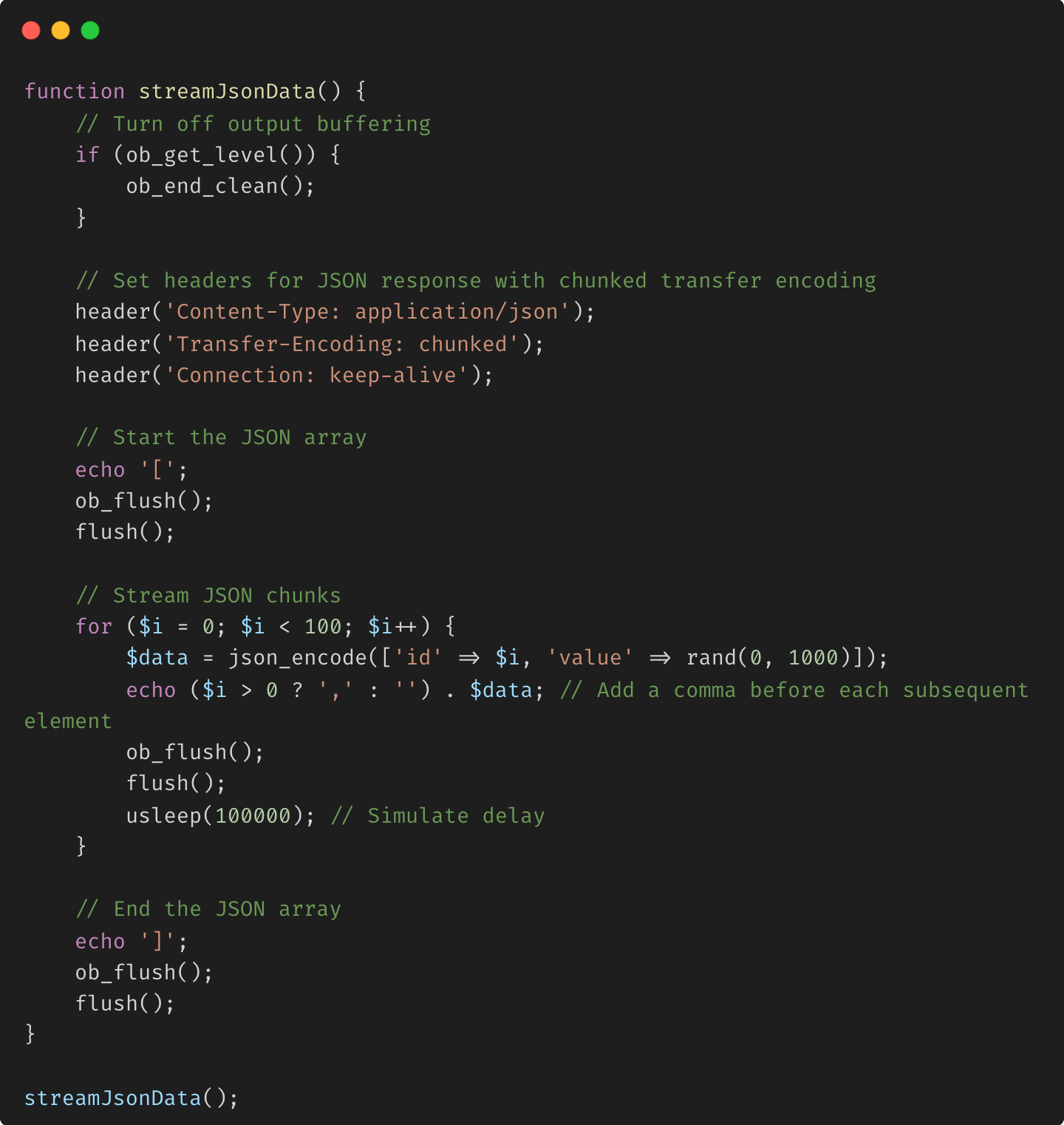
Explication :
Diffusion JSON : le tableau JSON est ouvert en premier ([), et chaque bloc de données est envoyé en tant qu'objet JSON individuel. Le tableau est fermé (]) une fois tous les blocs envoyés. JSON incrémental : cette méthode envoie chaque objet JSON au fur et à mesure de sa génération, ce qui peut être utile dans les API qui traitent de grands ensembles de données ou des tâches de génération de données de longue durée.
Cas d'utilisation :
Cette technique est utile pour les API qui doivent fournir de grands ensembles de données au format JSON mais qui souhaitent commencer à transmettre des données au client immédiatement plutôt que d'attendre que l'ensemble de données soit prêt.
Gestion des téléchargements de fichiers volumineux avec des données en streaming
Lors de la gestion des téléchargements de fichiers volumineux, vous pouvez utiliser le flux php://input de PHP pour lire les données entrantes par morceaux plutôt que de charger l'intégralité du fichier en mémoire.
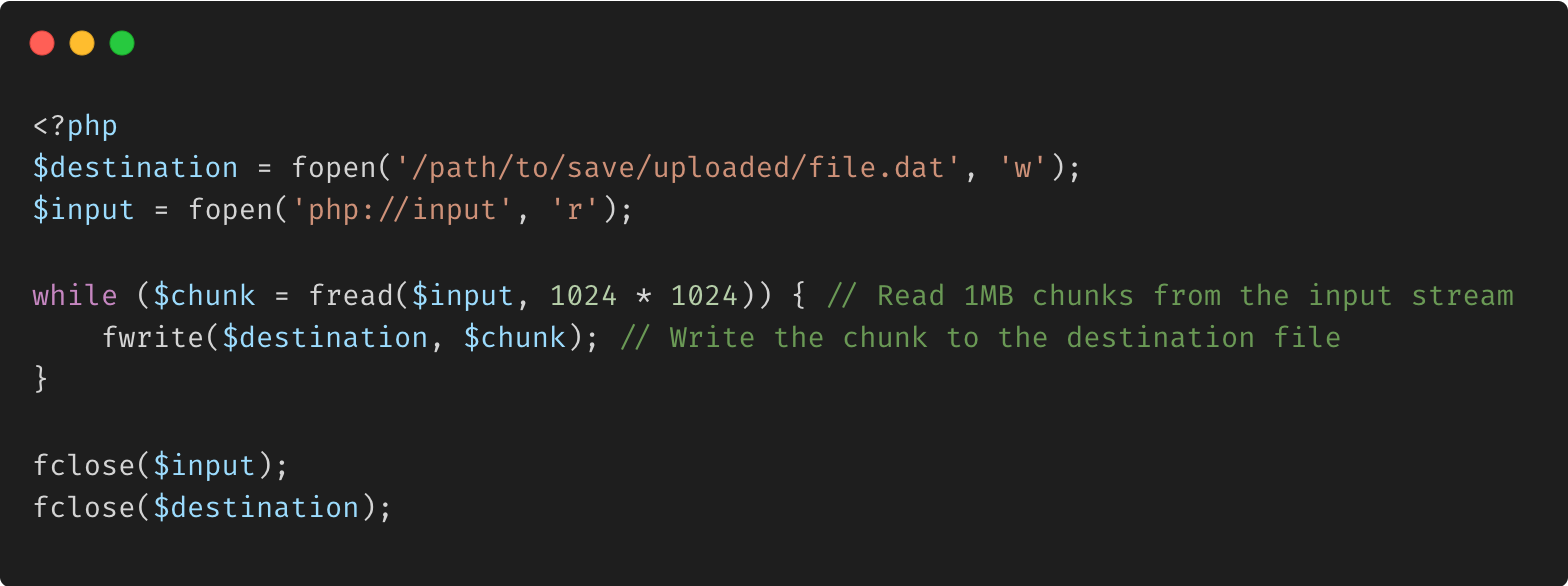
Explication :
php://input : ce flux vous permet d'accéder aux données POST brutes, ce qui est utile pour gérer directement les téléchargements de fichiers sans dépendre de $_FILES. Gestion des téléchargements en morceaux : la lecture et l'écriture du fichier en morceaux évitent au serveur de manquer de mémoire lors de la gestion de téléchargements volumineux.
Cas d'utilisation :
Cette technique est utile dans les scénarios où vous vous attendez à des téléchargements de fichiers volumineux (par exemple, des téléchargements de vidéos, des soumissions de grands ensembles de données) et souhaitez vous assurer que votre application peut les gérer efficacement sans problèmes de mémoire.
Événements envoyés par le serveur (SSE) avec PHP
Les événements envoyés par le serveur (SSE) permettent à un serveur de transmettre des mises à jour au client en temps réel via une connexion HTTP. SSE utilise un codage de transfert fragmenté pour envoyer des données en continu.

Pièges potentiels et bonnes pratiques
Pièges :
- Compatibilité client : bien que la plupart des navigateurs et clients HTTP modernes prennent en charge l'encodage de transfert en bloc, certains clients plus anciens peuvent ne pas le gérer correctement. Assurez-vous que votre application se dégrade correctement si l'encodage en bloc n'est pas pris en charge.
- Proxies intermédiaires : certains proxys ou pare-feu peuvent ne pas gérer correctement l'encodage de transfert en bloc, ce qui peut entraîner une corruption des données ou des transmissions incomplètes.
- Transmission incomplète : si la connexion est interrompue avant la réception du dernier bloc, le client peut se retrouver avec des données incomplètes. Mettez en œuvre une gestion des erreurs et des tentatives appropriées lorsque cela est possible.
Bonnes pratiques :
- Repli gracieux : implémentez des contrôles pour vous assurer que les clients peuvent gérer l'encodage de transfert en bloc. Si ce n'est pas le cas, envisagez d'envoyer la longueur totale du contenu ou de fournirune méthode de téléchargement alternative.
- Vider fréquemment : utilisez
flush()pour garantir que les données sont envoyées immédiatement au client, en particulier lors de la diffusion de fichiers volumineux. Cela évite de mettre en mémoire tampon de grandes quantités de données. - Surveiller les performances : surveillez régulièrement les performances de votre implémentation de transfert fragmenté pour identifier les goulots d'étranglement ou les problèmes, en particulier en cas de charge importante ou de fichiers volumineux.
- Considérations relatives à la sécurité : assurez-vous que les réponses fragmentées sont correctement validées et nettoyées, car le codage fragmenté peut parfois être exploité dans les attaques de contrebande de requêtes HTTP.
Dans la déduplication des données, la synchronisation des données et la compression des données à distance
Dans la déduplication des données, la synchronisation des données et la compression des données à distance, le découpage en morceaux est un processus de division d'un fichier en morceaux plus petits appelés morceaux à l'aide d'un algorithme de découpage en morceaux. Cela permet d'éliminer les copies en double de données répétitives sur le stockage ou de réduire la quantité de données envoyées sur le réseau en sélectionnant uniquement les morceaux modifiés. Les algorithmes de segmentation par contenu (CDC), tels que le hachage rotatif et ses variantes, sont les algorithmes de déduplication les plus populaires depuis 15 ans.
Déduplication des données
La déduplication des données est un processus utilisé pour éliminer les copies redondantes des données, réduisant ainsi les besoins de stockage. La segmentation joue un rôle important dans ce processus en décomposant les fichiers en segments plus petits, ce qui permet au système d'identifier et de stocker uniquement les segments uniques.
Types de segmentation dans la déduplication :
- Segmentation à taille fixe : le fichier est divisé en segments de taille fixe, par exemple 4 Ko ou 8 Ko.
- Segmentation à taille variable (Segmentation par contenu défini) : le fichier est divisé en fonction du contenu, où les limites des segments sont déterminées par le contenu lui-même, souvent à l'aide d'algorithmes comme l'empreinte digitale de Rabin.
Exemple avec segmentation à taille fixe :
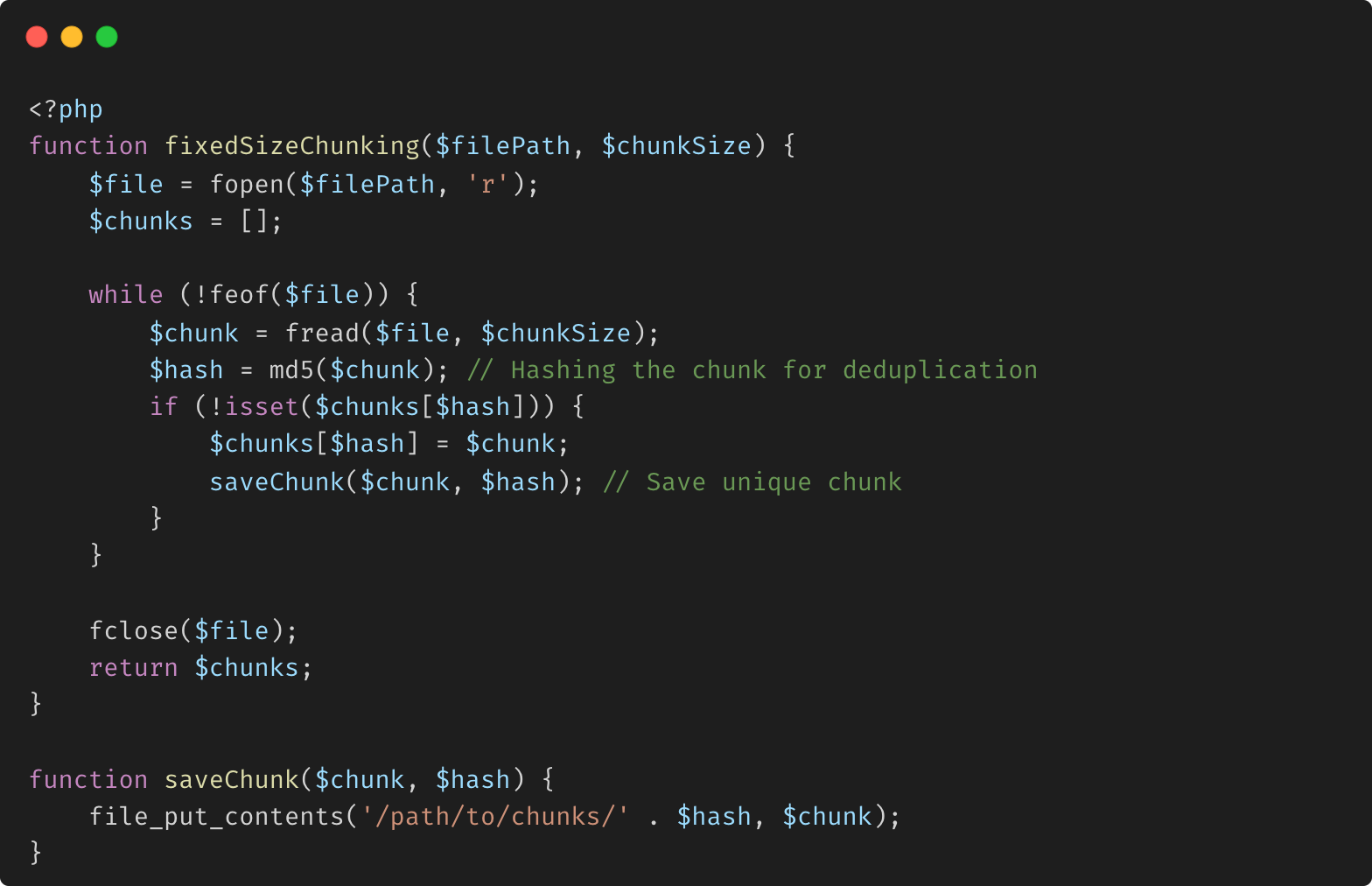
Explication :
Chunking à taille fixe : cette méthode divise le fichier en segments de taille fixe, puis hache chaque segment. Si un segment est unique, il est enregistré ; sinon, il est supprimé, évitant ainsi le stockage redondant.
Avantages du découpage en segments dans la déduplication :
Efficacité du stockage : réduit la quantité d'espace disque requise en éliminant les données redondantes.
Sauvegardes plus rapides : étant donné que seuls les segments uniques sont stockés, les sauvegardes peuvent être plus rapides et nécessiter moins de stockage.
Déduplication avancée :
Chunking à taille variable : au lieu d'une taille fixe, le découpage à taille variable utilise des méthodes de découpage basées sur le contenu. Il est plus efficace pour identifier les données en double dans les fichiers où un contenu similaire peut être légèrement décalé (par exemple, dans les bases de données).
Synchronisation des données
La synchronisation des données consiste à maintenir plusieurs ensembles de données synchronisés sur différents systèmes ou emplacements. Le découpage en blocs est essentiel dans ce contexte pour garantir que seuls les blocs de données modifiés ou nouveaux sont transférés, minimisant ainsi la bande passante et le temps de traitement.
Exemple de synchronisation avec un comportement de type Rsync :
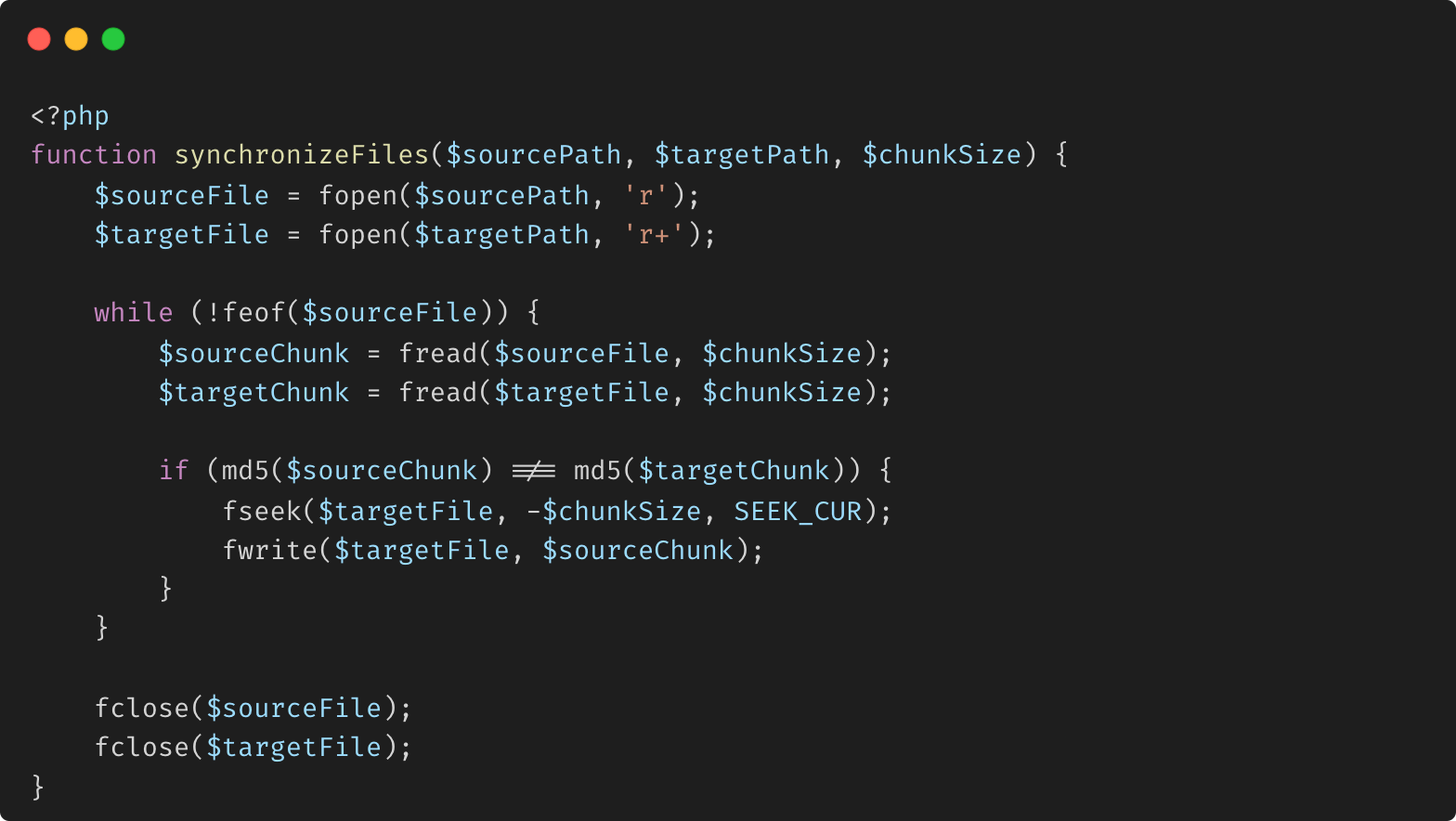
Explication :
Synchronisation par blocs : cette méthode lit les fichiers source et cible en blocs, les compare et met à jour uniquement les blocs qui diffèrent. Cela imite le comportement d'outils comme rsync, qui sont très efficaces pour synchroniser de grands ensembles de données.
Avantages du découpage en blocs dans la synchronisation :
Efficacité de la bande passante : seuls les blocs modifiés sont transmis, ce qui réduit la quantité de données envoyées sur le réseau. Temps de synchronisation réduit : en transférant uniquement ce qui est nécessaire, le processus de synchronisation est plus rapide.
Compression des données à distance
La compression des données à distance est le processus de compression des données avant de les envoyer sur un réseau, souvent utilisé dans des scénarios tels que la diffusion de contenu Web, le stockage dans le cloud et les sauvegardes à distance. Le découpage en blocs peut être appliqué ici pour compresser les données en segments, permettant un traitement plus efficace et parallèle.
Exemple d'utilisation de Gzip pour la compression en morceaux :
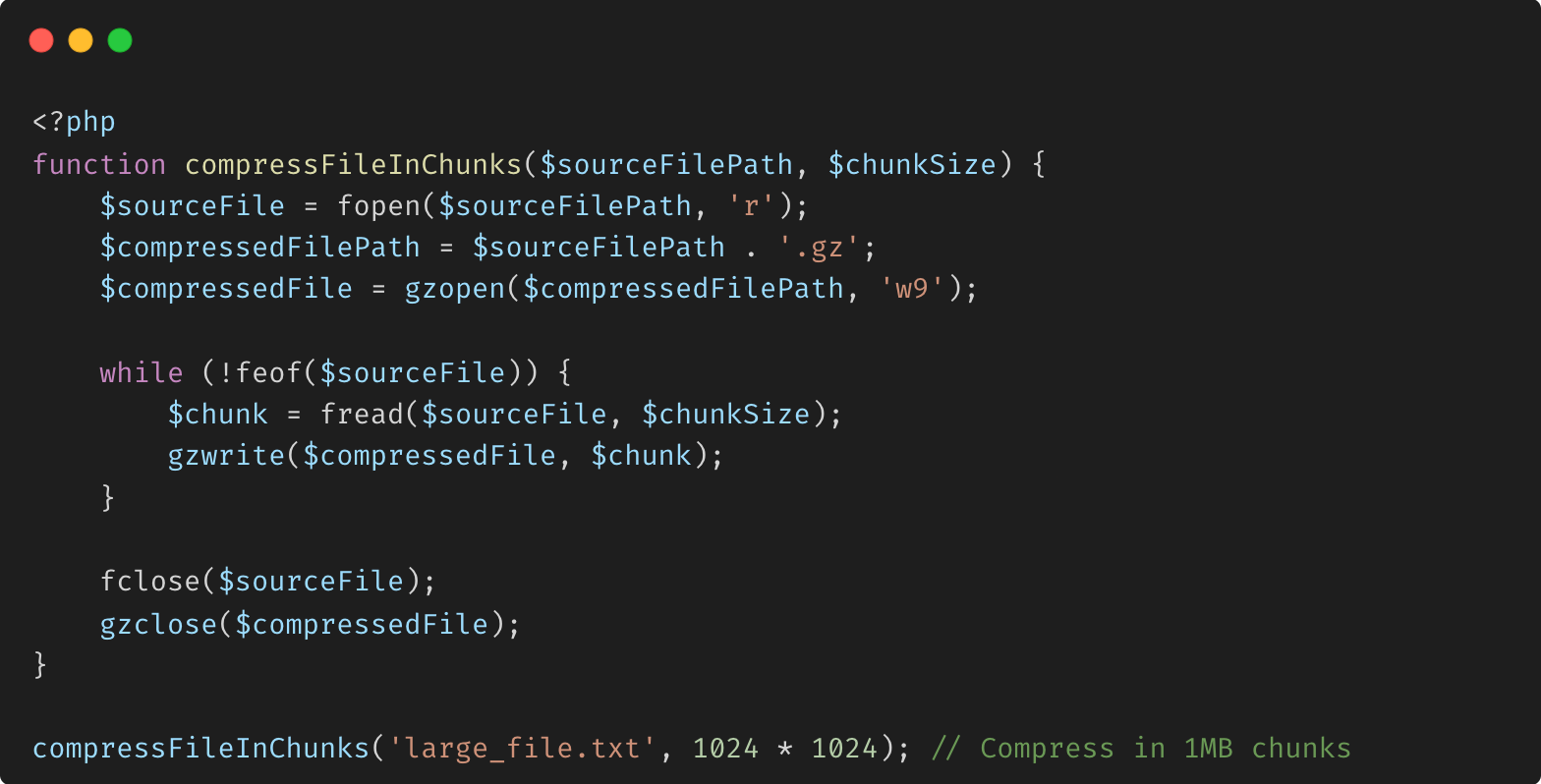
Explication :
Compression en morceaux : le fichier est lu et compressé en morceaux, ce qui peut être particulièrement utile pour les fichiers très volumineux ou lorsque les contraintes de mémoire sont un problème.
Avantages de la compression en morceaux :
Efficacité de la mémoire : en compressant les données en morceaux, le fichier entier n'a pas besoin d'être chargé en mémoire, ce qui le rend adapté aux grands ensembles de données. Traitement parallèle : la compression par blocs peut être parallélisée, ce qui améliore les performances sur les systèmes multicœurs.
Exemple avancé : segmentation par contenu (CDC)
Les algorithmes de segmentation par contenu (CDC), tels que l'empreinte Rabin, divisent les données en fonction du contenu plutôt que de tailles fixes, ce qui les rend plus efficaces pour la déduplication et la synchronisation dans les scénarios où les données sont fréquemment mises à jour avec de petites modifications.
Exemple avec segmentation par contenu :
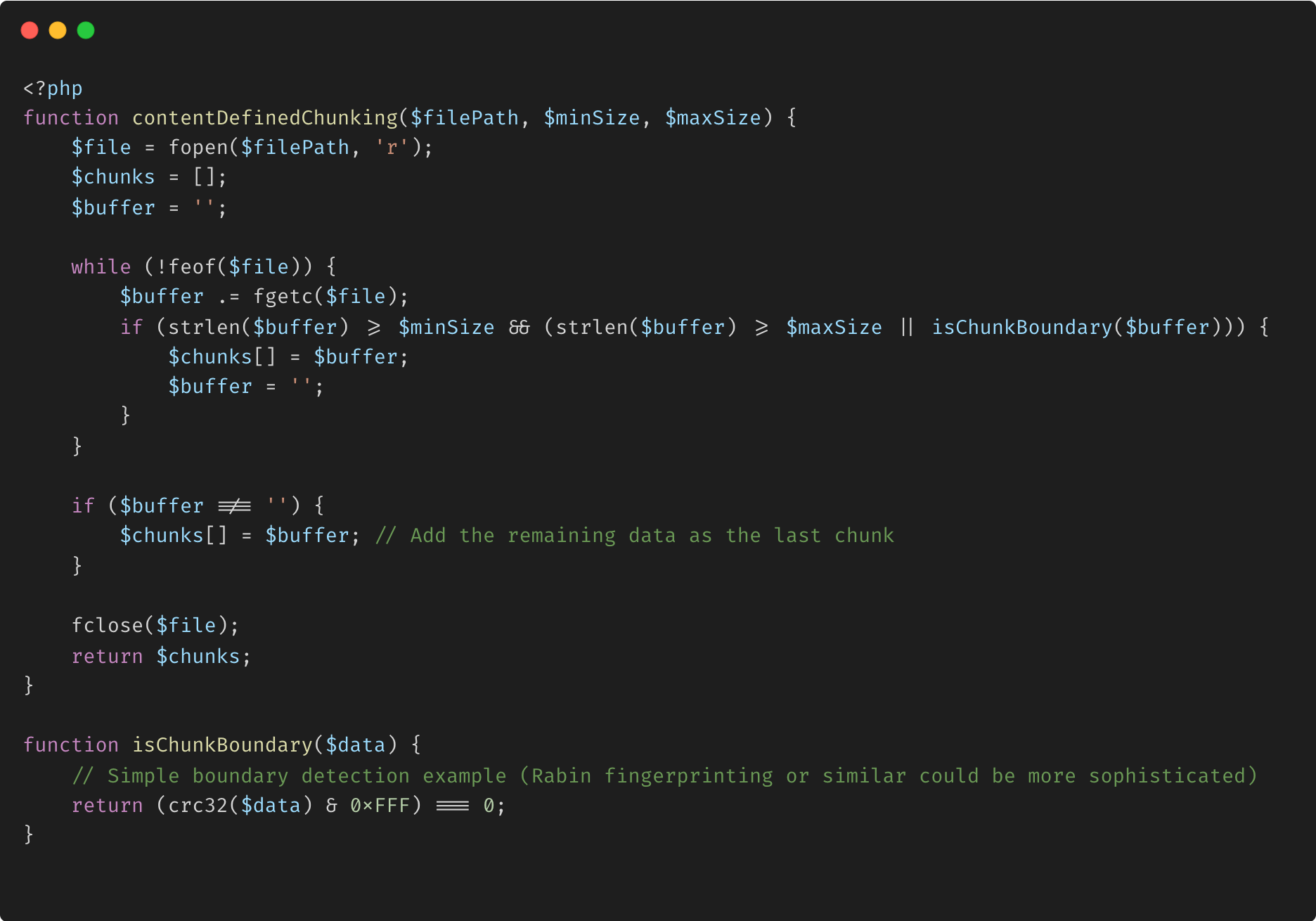
Explication :
Limites définies par le contenu : cet exemple illustre une implémentation de base de CDC, où les blocs sont déterminés par le contenu plutôt que par des tailles fixes. La détection des limites pourrait être plus sophistiquée en utilisant un véritable algorithme comme l'empreinte digitale Rabin. Tailles de blocs adaptatives : CDC adapte les tailles de blocs en fonction du contenu, ce qui le rend plus efficace pour détecter le contenu dupliqué dans les fichiers avec des données similaires mais pas identiques.
Avantages :
Déduplication améliorée : CDC est plus efficace que le découpage en blocs de taille fixe pour détecter la redondance dans les fichiers dont le contenu a légèrement changé. Synchronisation efficace : lorsque les fichiers ont été mis à jour avec de petites modifications, CDC garantit que seul le contenu modifié est transmis, optimisant ainsi davantage les processus de synchronisation.
Découpage avec les services cloud
De nombreuses solutions modernes de stockage et de sauvegarde dans le cloud utilisent le découpage en blocs en conjonction avec la déduplication et la compression pour optimiser l'utilisation du stockage et de la bande passante.
Exemple avec le téléchargement en plusieurs parties d'AWS S3 : lors du téléchargement de fichiers volumineux sur AWS S3, la fonction de téléchargement en plusieurs parties permet de télécharger les fichiers en blocs, ce qui facilite la gestion des fichiers volumineux, la reprise des téléchargements et la réduction de l'impact des problèmes de réseau.
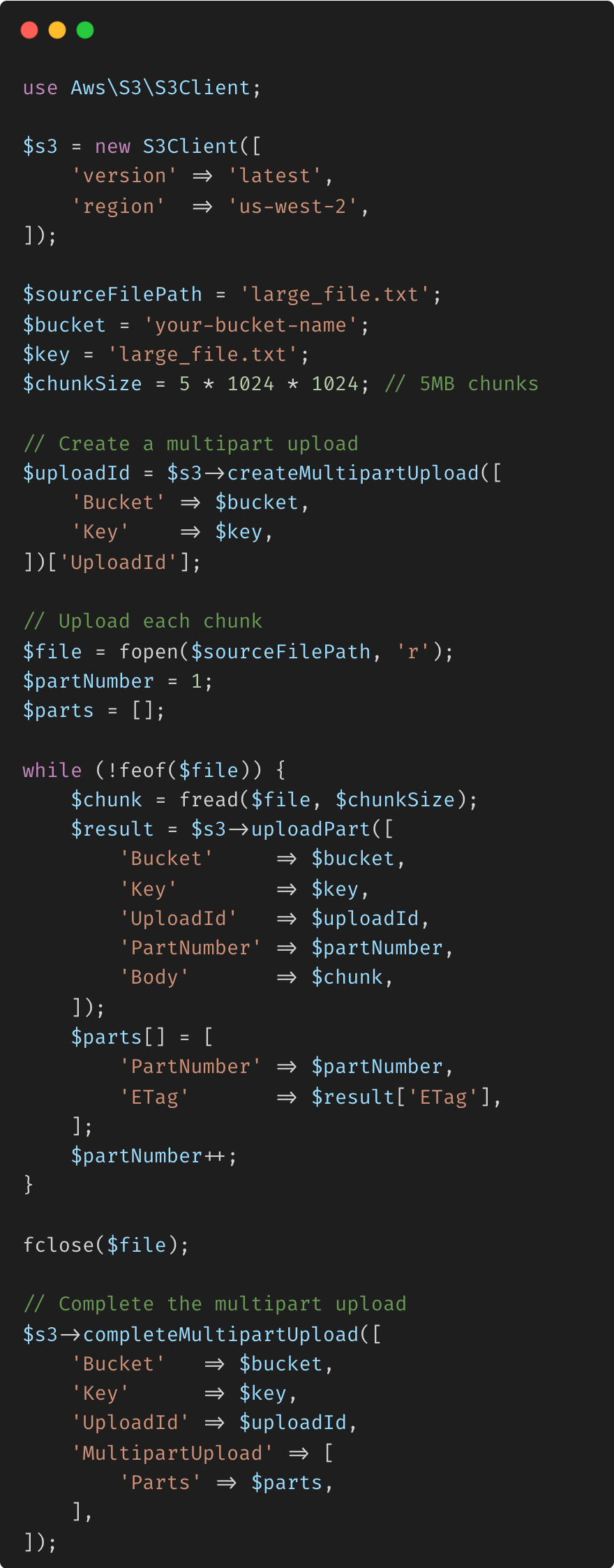
Explication :
Téléchargement en plusieurs parties : cet exemple montre comment télécharger un fichier volumineux sur S3 en morceaux, chacun d'une taille de 5 Mo. Cette approche est robuste, permettant de nouvelles tentatives sur des parties individuelles si le téléchargement échoue et rendant le processus de téléchargement plus efficace et plus fiable. Avantages :
Évolutivité : gère les fichiers volumineux qui pourraient autrement provoquer des dépassements de délai ou dépasser les limites de mémoire. Résilience : la possibilité de reprendre les téléchargements ayant échoué au niveau des parties minimise l'impact des perturbations du réseau.
alexandre-daubois : Lazy streams
Lors de sa récente présentation, Alexandre Daubois, Lead Symfony Developer chez Wanadev Digital, a évoqué les défis et les solutions auxquels son équipe a été confrontée lors du déplacement de son application de modélisation de maisons en 3D vers le cloud. L'accent a été mis principalement sur la gestion efficace de fichiers JSON volumineux, une exigence essentielle compte tenu de la lourdeur de l'applicationta utilisation.
-
Principaux défis L'application nécessitait le stockage de fichiers JSON massifs contenant des modèles 3D et des textures, qui fonctionnaient initialement bien avec le stockage local. Cependant, le passage au cloud a introduit des obstacles importants, notamment en matière de génération et de déploiement de fichiers. L'approche traditionnelle consistant à créer l'intégralité du fichier JSON en mémoire n'était plus viable, car elle entraînait des débordements de mémoire lorsque les fichiers devenaient trop volumineux.
-
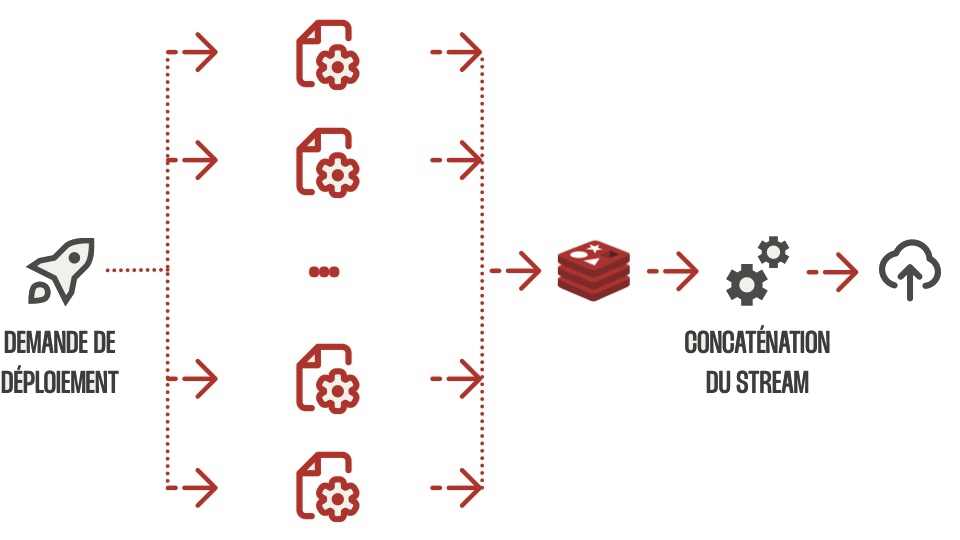
Redis Streams à la rescousse La solution s'est présentée sous la forme de Redis Streams. Redis, initialement utilisé uniquement pour le stockage de session, s'est avéré idéal pour ce nouveau cas d'utilisation en raison de sa structure de données en mémoire à grande vitesse. Redis Streams a permis à l'équipe de décomposer les fichiers JSON volumineux en morceaux plus petits qui pouvaient être traités simultanément par plusieurs pods dans le cloud. Chaque morceau était géré par un travailleur, sérialisé et stocké dans le flux Redis.
-
La mise en œuvre Le processus impliquait que plusieurs travailleurs génèrent des segments JSON qui étaient ensuite consolidés dans le flux Redis. Cette approche a réparti la charge de travail sur plusieurs pods, garantissant qu'aucune instance ne manquerait de mémoire. Une fois tous les segments générés, l'étape finale consistait à concaténer les morceaux et à les télécharger sur le stockage cloud. Cependant, l'équipe a rencontré un autre défi lorsqu'elle a essayé de fusionner toutes les données en un seul fichier en raison des limites de mémoire.
-
Lazy Stream : une solution personnalisée Pour résoudre ce problème, Daubois a développé une bibliothèque personnalisée appelée Lazy Stream, qui permettait l'écriture de fichiers fragmentés directement sur le stockage cloud. Cette approche évitait les débordements de mémoire en écrivant séquentiellement les données du flux Redis dans le fichier JSON final, en téléchargeant chaque morceau au fur et à mesure de son traitement. Cette méthode garantissait que même les fichiers extrêmement volumineux pouvaient être traités efficacement sans épuiser les ressources système.
La bibliothèque PHP fournie implémente une série de classes sous l'espace de noms « LazyStream », conçue pour une gestion efficace et paresseuse des flux. Les classes incluent LazyStreamChunkWriter, LazyStreamReader, LazyStreamWriter et MultiLazyStreamWriter, chacune offrant des méthodes spécialisées pour travailler avec des flux de manière efficace en termes de mémoire. La bibliothèque permet de lire et d'écrire dans des flux de manière incrémentielle, en utilisant des générateurs pour gérer les données selon les besoins plutôt que de tout charger en mémoire en une seule fois. Cette approche est particulièrement utile pour traiter de grands ensembles de données ou travailler avec plusieurs flux simultanément, comme le montre la classe MultiLazyStreamWriter, qui gère l'écriture sur plusieurs flux simultanément avec un seul fournisseur de données. De plus, des fonctionnalités telles que la fermeture automatique des flux et la gestion des données binaires améliorent la flexibilité, ce qui rend cette bibliothèque adaptée aux opérations de streaming complexes tout en maintenant une faible utilisation des ressources.
-
Gestion des flux paresseux : la bibliothèque se concentre sur la gestion des flux de manière paresseuse, ce qui signifie qu'elle traite les données de manière incrémentielle à l'aide de générateurs, ce qui permet de gérer efficacement la mémoire, en particulier pour les grands ensembles de données.
-
Types de flux multiples : elle fournit différentes classes pour la lecture et l'écriture de flux, notamment
LazyStreamReader,LazyStreamWriter,LazyStreamChunkWriteretMultiLazyStreamWriter, chacune adaptée à des cas d'utilisation spécifiques. -
Écriture en morceaux : la classe
LazyStreamChunkWriterpermet d'écrire les données en morceaux, en envoyant les données au fur et à mesure de leur génération plutôt que de les exiger toutes à l'avance. -
Prise en charge de plusieurs flux : la classe
MultiLazyStreamWriterpeut écrire des données dans plusieurs flux simultanément à l'aide d'un seul fournisseur de données, ce qui est utile pour dupliquer des données sur plusieurs destinations. -
Gestion automatique des flux : la bibliothèque comprend des fonctionnalités telles que l'ouverture, la fermeture et la gestion des erreurs automatiques des flux, simplifiant la gestion des ressources de flux.
-
Comportement personnalisable : les utilisateurs peuvent contrôler des aspects tels que la fermeture automatique des flux et la lecture en mode binaire, offrant une flexibilité dans la gestion des flux.
Vous trouverez ci-dessous un exemple d'utilisation de base de la classe LazyStreamChunkWriter pour écrire des données dans un fichier :
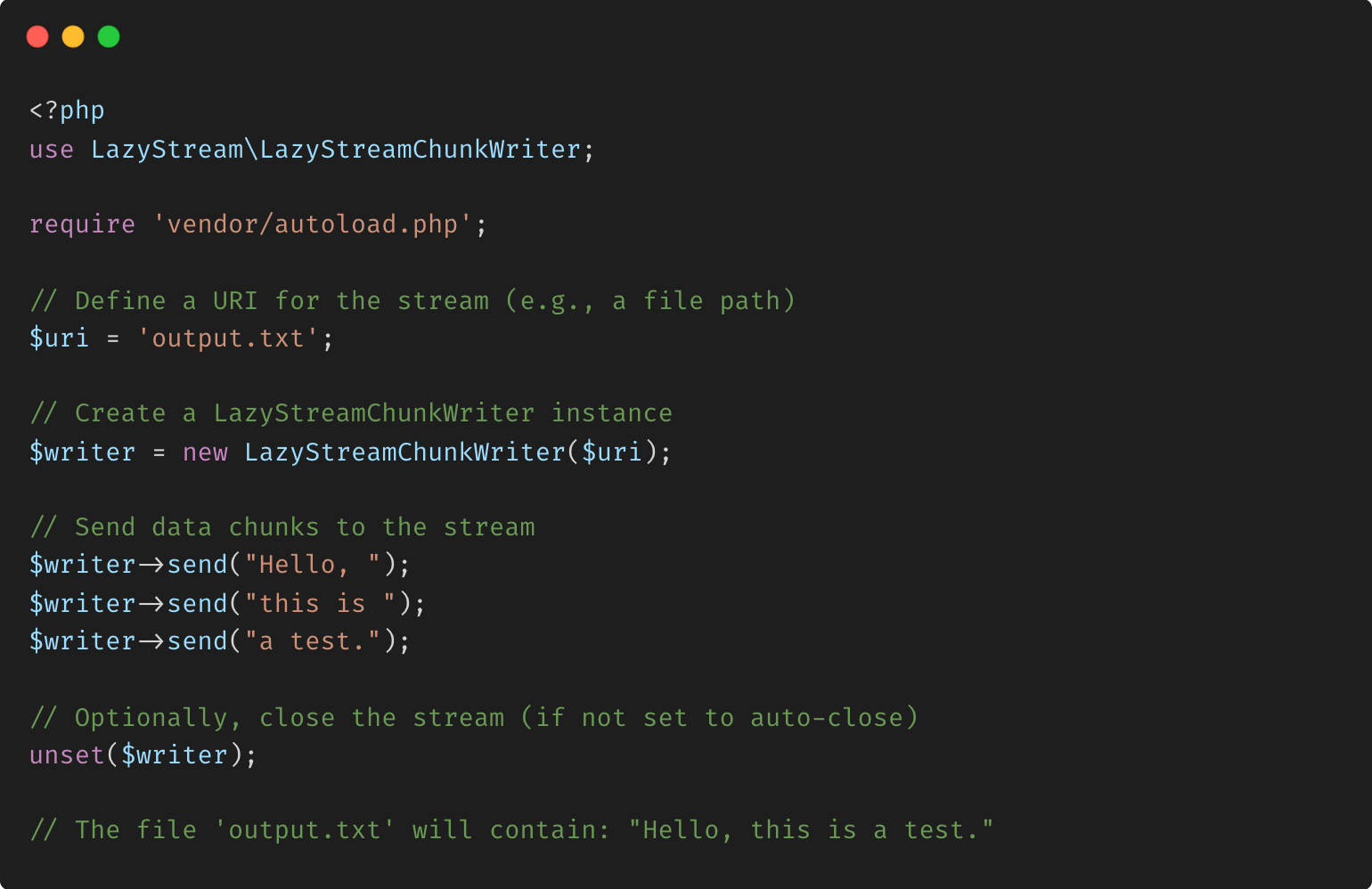
Explication
Dans cet exemple :
- Nous créons une instance de
LazyStreamChunkWriteravec un URI de fichier. - Nous utilisons la méthode
send()pour écrire des données dans le flux par morceaux. - Le flux est automatiquement ouvert en cas de besoin et éventuellement fermé en fonction de la configuration.
Cet exemple démontre la capacité d'écriture incrémentielle des données de la bibliothèque, ce qui la rend idéale pour les situations où vous souhaitez traiter ou générer des données progressivement.
-
Conclusion La combinaison de Redis Streams et de la bibliothèque Lazy Stream a permis à Wanadev Digital de surmonter les défis importants de la migration vers le cloud. En exploitant Redis pour sa vitesse en mémoire et en utilisant Lazy Stream pour les téléchargements fragmentés, l'équipe a réussi à faire évoluer son application, permettant une gestion robuste et efficace des fichiers JSON volumineux dans un environnement cloud.
-
Points forts des questions-réponses :
Gestion frontale des fichiers volumineux : les utilisateurs passent généralement plusieurs heures sur l'application, ce qui rend le temps de chargement initial acceptable. Les projets futurs incluent la transition vers la livraison de données basée sur l'API avec mise en cache et prise en charge du CDN pour des performances améliorées. Cette solution est désormais une pierre angulaire de leur architecture basée sur le cloud, illustrant la puissance de la combinaison de Redis avec le développement personnalisé pour résoudre des problèmes complexes.
- Code exemple
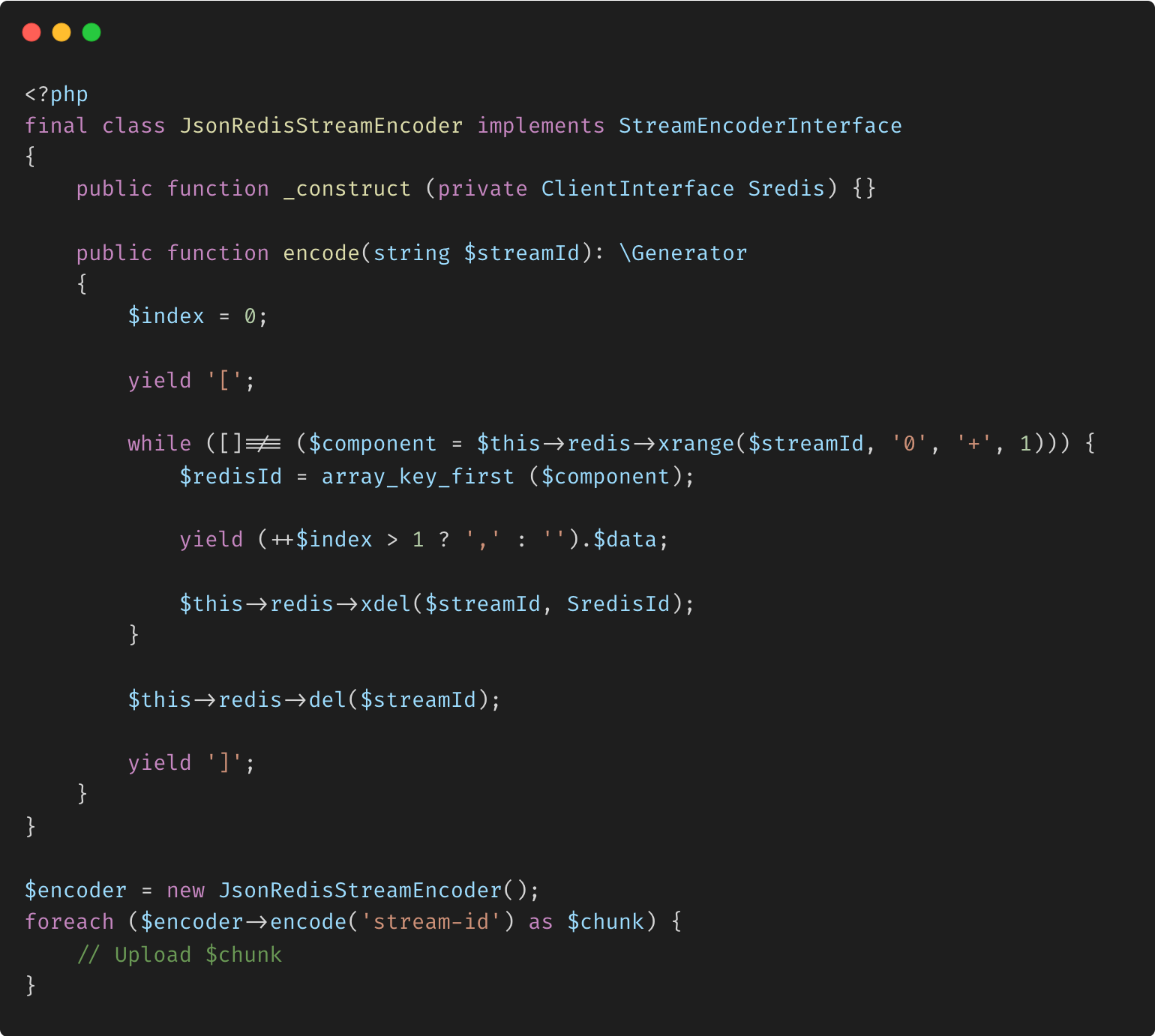
La classe JsonRedisStreamEncoder dans ce code PHP fournit un moyen efficace de convertir les données d'un flux Redis en un format de tableau JSON tout en minimisant l'utilisation de la mémoire. En implémentant un générateur dans la méthode encode, la classe traite les données du flux Redis de manière incrémentielle, produisant de petits morceaux JSON un par un. La méthode génère d'abord un crochet d'ouverture [, puis entre dans une boucle qui récupère, formate et génère chaque entrée de flux sous forme d'élément JSON, en ajoutant une virgule entre les éléments selon les besoins. Après avoir généré chaque morceau, l'entrée est supprimée du flux pour libérer de la mémoire. Une fois toutes les données traitées, la méthode supprime l'intégralité du flux de Redis et génère le crochet de fermeture ] pour compléter le tableau JSON. Ce traitement incrémentiel permet une gestion efficace des grands ensembles de données, ce qui rend la classe particulièrement utile dans les environnements cloud où de grands fichiers JSON doivent être générés sans provoquer de dépassements de mémoire. L'exemple d'utilisation montre comment la méthode encode peut être itérée avec une boucle foreach, permettant aux blocs JSON d'être téléchargés ou traités séquentiellement.
matyo91 : Offres mises en cache
Le code fourni est une classe PHP chargée de gérer l'accès au catalogue et son affichage sur un site extranet. Il interagit avec divers services externes, dont Google BigQuery, pour récupérer et présenter les données du catalogue en fonction des entrées et des filtres des utilisateurs. La classe gère des opérations telles que la liste des éléments, la gestion de la pagination, l'application de critères de recherche et de filtrage et la récupération efficace de grands ensembles de données grâce à des mécanismes de segmentation et de mise en cache. En s'intégrant à Google BigQuery, tLa classe garantit que les informations du catalogue sont à jour et optimisées pour les performances, améliorant ainsi l'expérience utilisateur sur la plateforme.
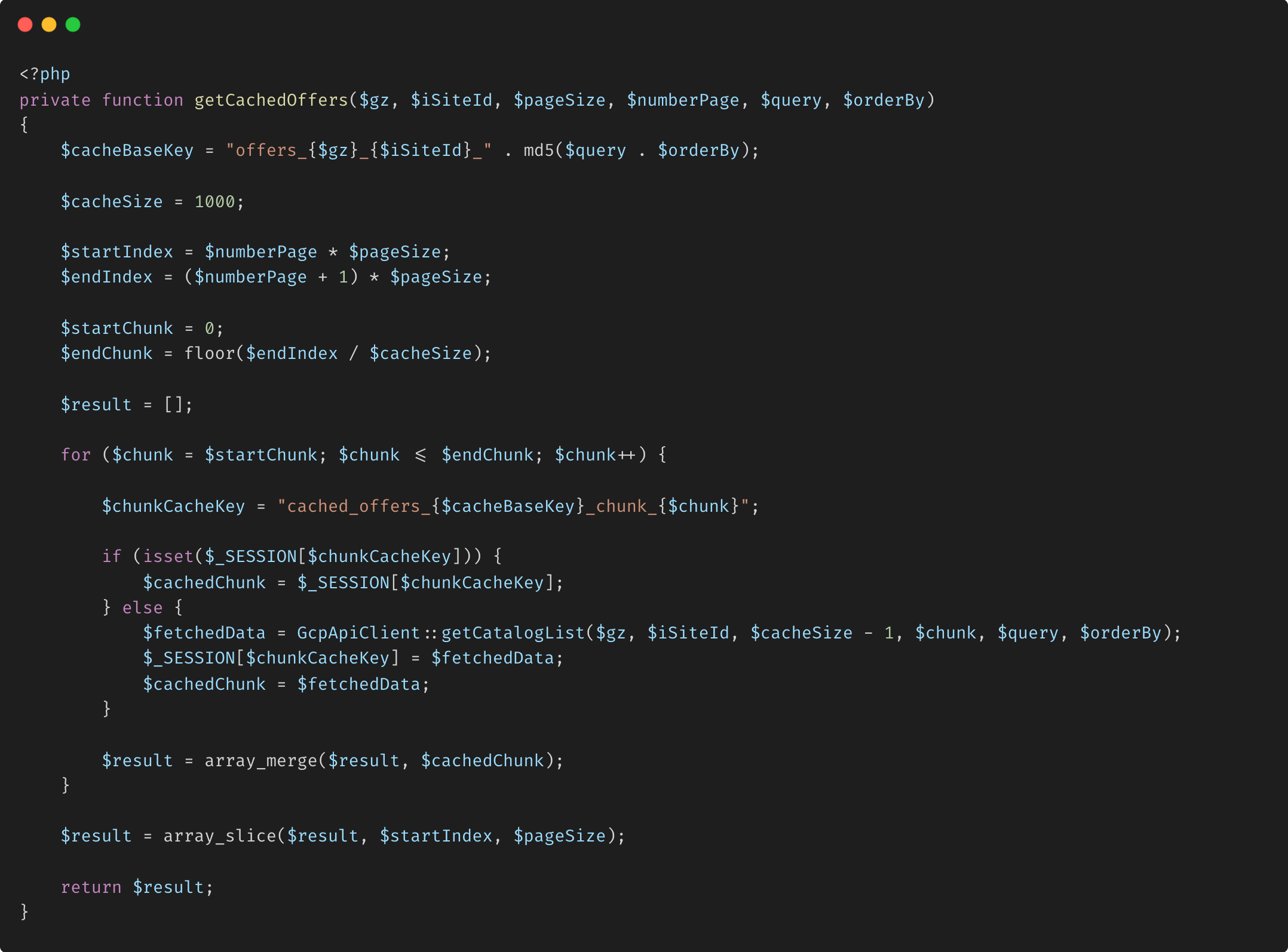
Explication de l'implémentation du découpage en blocs :
-
Définir la taille du bloc Le code définit une taille de bloc de 1 000 éléments (
$cacheSize = 1000;). Cette taille détermine le nombre d'éléments traités à la fois. -
Calculer les index Les variables
$startIndexet$endIndexdéfinissent la plage d'éléments à récupérer pour la page en cours. Ces index aident à déterminer les blocs à récupérer. -
Boucle sur les blocs La boucle
forparcourt les blocs requis, de$startChunkà$endChunk. À chaque itération, le système vérifie si le bloc est déjà mis en cache (stocké dans$_SESSION). Si ce n'est pas mis en cache, le fragment est récupéré à l'aide d'un appel API. -
Résultats de la fusion Les fragments récupérés sont fusionnés en un seul tableau (
$result). Enfin, le tableau est découpé pour extraire uniquement les éléments pertinents pour la page en cours, garantissant une utilisation optimale de la mémoire. -
Renvoyer le résultat La fonction
getCachedOffers()renvoie le tableau découpé, qui contient les données à afficher sur la page en cours.
Différence entre les données de bloc et de tampon
Commençons par en discuter dans le contexte de JavaScript. JavaScript ne dispose pas d'un mécanisme intégré pour gérer et manipuler les données binaires. Par conséquent, un mécanisme était nécessaire. Nous avons un module global dans JavaScript appelé "buffer" qui gère toutes les données binaires. Le tampon est généralement une mémoire temporaire dans la RAM qui traite les données binaires à l'aide de blocs. Les blocs sont de petits morceaux de données binaires qui voyagent de la source à la destination à l'aide d'un flux.
Bloc : un bloc est un petit morceau de données binaires que nous voulons transférer de la source à la destination. Ainsi, nous avons un mécanisme appelé « chunks » qui contient ces petites données binaires et voyage de la source à la destination en utilisant des flux. Les chunks contiennent toutes les informations sur les données binaires, telles que les chunks qui doivent être traités et ceux qui ne le doivent pas.
Buffer : un buffer est une mémoire temporaire dans la RAM qui gère les données de chunk et les envoie pour traitement. Le buffer est un très petit bloc de mémoire adapté aux données binaires. Si le buffer est plein, les données sont envoyées pour traitement. Parfois, le buffer est utilisé comme middleware entre le traitement des données et la réception car un processeur est nécessaire pour le traitement des données.
Les chunks et les buffers diffèrent de plusieurs manières :
- Nature : les chunks sont des morceaux de données binaires, tandis que les buffers sont une classe globale dans Node.js utilisée pour gérer ces données binaires.
- Contenu : les chunks ne contiennent que des données binaires, tandis que les buffers peuvent gérer des données au format binaire ainsi que d'autres formats.
- Gestion : les chunks sont au format octet et doivent être gérés avec soin pour éviter la corruption des données. Les buffers gèrent les exceptions qui peuvent survenir lors de la gestion des chunks.
- Dépendance : les blocs sont des conteneurs indépendants gérés par des tampons, tandis que les tampons s'appuient sur des blocs ou des flux pour le transfert de données.
- Utilisation : les blocs sont utilisés pour la récupération de données externes, tandis que les tampons formatent et récupèrent des données sous diverses formes.
- Contrôle : les blocs ont un flux incontrôlé, mais les tampons permettent de contrôler le flux de données à travers les flux.
- Création : les blocs ne peuvent pas être créés directement, mais les tampons peuvent être créés pour contenir des blocs.
- Exemple : dans
<Buffer 48 65 6c 6c 6f>, la partie soulignée est un bloc, tandis que l'ensemble du contenu entre les crochets angulaires est un tampon. - Taille : un bloc stocke un octet de données, tandis que la taille d'un tampon dépend de la RAM et du matériel de la machine.
Différence entre bloc et thunk
En programmation informatique, un thunk est une sous-routine utilisée pour injecter un calcul dans une autre sous-routine. Les thunks sont principalement utilisés pour retarder un calcul jusqu'à ce que son résultat soit nécessaire, ou pour insérer des opérations au début ou à la fin de l'autre sous-routine.Ils ont de nombreuses autres applications dans la génération de code de compilateur et la programmation modulaire.
- Applications
Bien que l'industrie du logiciel ait largement standardisé l'évaluation par appel par valeur et par référence, l'étude active de l'appel par nom s'est poursuivie dans la communauté de la programmation fonctionnelle. Cette recherche a produit une série de langages de programmation d'évaluation paresseuse dans lesquels une variante de l'appel par nom est la stratégie d'évaluation standard. Les compilateurs de ces langages, tels que le compilateur Glasgow Haskell, se sont largement appuyés sur les thunks, avec la fonctionnalité supplémentaire que les thunks enregistrent leur résultat initial afin de pouvoir éviter de le recalculer ; [6] c'est ce qu'on appelle la mémorisation ou l'appel par besoin.
Les langages de programmation fonctionnelle ont également permis aux programmeurs de générer explicitement des thunks. Cela se fait dans le code source en enveloppant une expression d'argument dans une fonction anonyme qui n'a pas ses propres paramètres. Cela empêche l'expression d'être évaluée jusqu'à ce qu'une fonction réceptrice appelle la fonction anonyme, obtenant ainsi le même effet que l'appel par nom. L'adoption de fonctions anonymes dans d'autres langages de programmation a rendu cette capacité largement disponible.
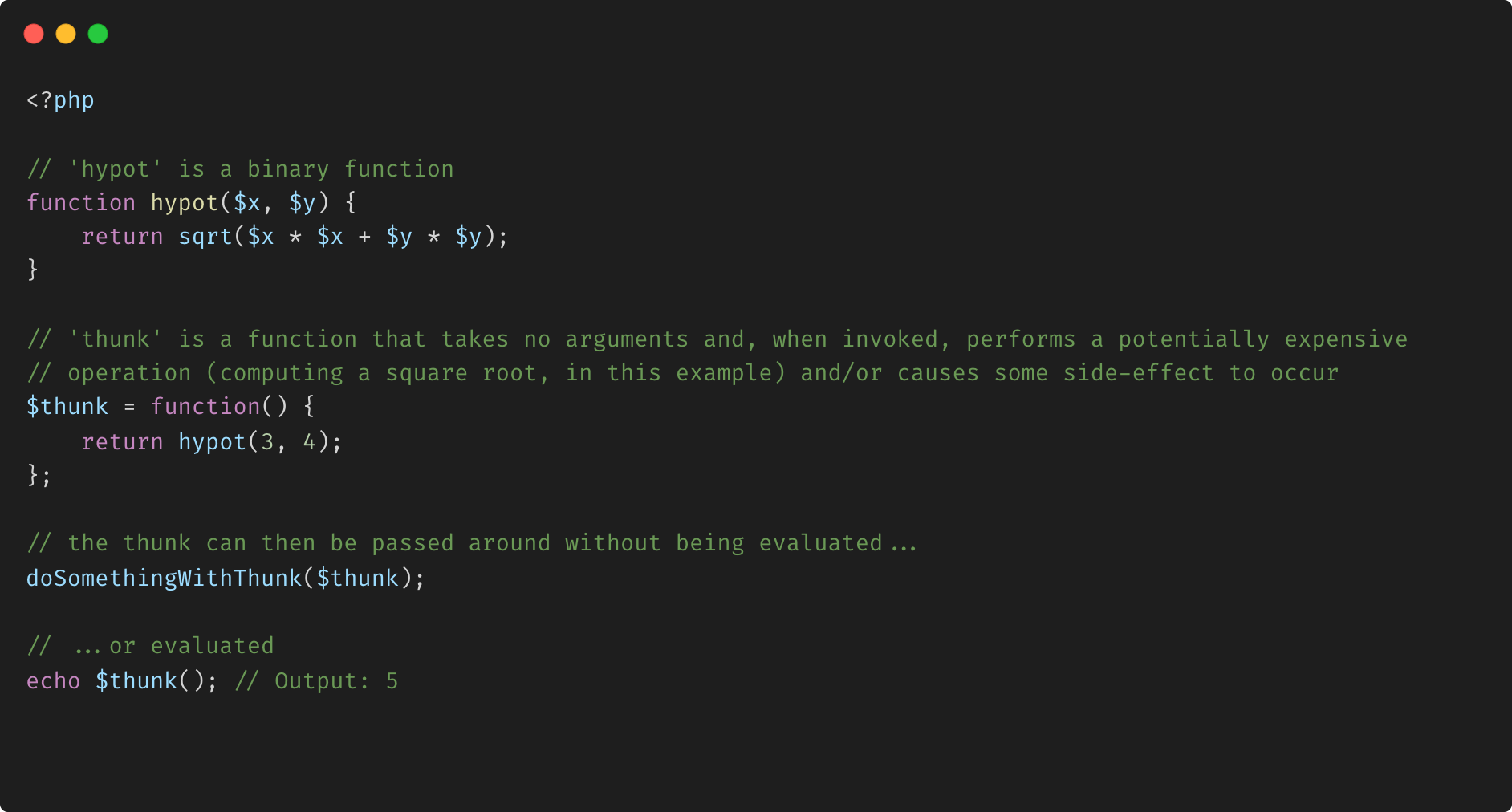
Résumé
En conclusion, les chunks jouent un rôle essentiel dans de nombreux domaines technologiques, allant du développement de logiciels à la gestion de la mémoire. Ils offrent un moyen de rendre le traitement des données plus efficace, structuré et fiable. Qu'il s'agisse de décomposer des fichiers de données, de comprendre des concepts complexes en psychologie ou de traiter efficacement des données en streaming, la méthode de fragmentation offre un moyen puissant de simplifier les tâches et de gérer efficacement de grandes quantités d'informations.
Foire aux questions (FAQ)
Q1 : Qu'est-ce qu'un fragment dans le contexte de la technologie ? R1 : Un fragment, dans le contexte de la technologie, fait référence à une quantité spécifique de données qui sont manipulées, transmises ou traitées comme une seule entité. Il peut s'agir d'une partie d'un fichier, d'un paquet de données envoyé sur un réseau ou d'un élément d'information traité par un logiciel.
Q2 : Comment le fragmentation améliore-t-elle la gestion des données ? R2 : Le fragmentation des données peut rendre les processus plus efficaces car il permet la transmission ou la gestion simultanée de plusieurs paquets de données. Il peut également réduire les erreurs, faciliter la récupération des données et améliorer la vitesse globale de traitement des données.
Q3 : Qu'est-ce que le fragmentation des données dans les réseaux ? R3 : Dans les réseaux, le fragmentation des données fait souvent référence au processus de décomposition d'un fichier de données volumineux en « morceaux » plus petits qui peuvent être transmis séparément sur un réseau. Cela permet une transmission de données plus fiable car cela réduit l'impact d'un seul paquet de données perdu ou corrompu.
Q4 : Comment fonctionne le découpage en blocs dans la programmation ? A4 : En programmation, le découpage en blocs peut être utilisé pour décomposer un processus ou une tâche volumineux en « blocs » plus petits et plus faciles à gérer. Cela peut rendre le codage de programmes complexes plus simple et plus efficace. Il peut également être utilisé pour gérer plus efficacement l'utilisation de la mémoire.
Q5 : Quel est le rôle des blocs dans le stockage informatique ? A5 : Dans le contexte du stockage informatique, les blocs font souvent référence aux unités de données que les systèmes de stockage lisent et écrivent en tant que groupe. Le découpage en blocs peut optimiser l'utilisation de l'espace de stockage sur disque et améliorer les performances du système.
Q6 : Le découpage en blocs est-il applicable à tous les types de traitement de données ? A6 : Pas nécessairement. L'application du découpage en blocs dépend de la nature des données, des exigences spécifiques d'un processus ou d'une tâche donnée et des caractéristiques du système utilisé.
Q7 : Quels sont les inconvénients potentiels du découpage en blocs ? A7 : Bien que le découpage puisse améliorer l'efficacité, il peut également entraîner des complications s'il n'est pas effectué correctement. Lorsque des fichiers volumineux sont découpés de manière incorrecte, cela peut entraîner des problèmes tels que la redondance des données, la perte de données et des difficultés lors du réassemblage des données.
Ressources liées à l'article
- Articles
- What is a chunk (coursera) https://www.coursera.org/lecture/learning-how-to-learn/2-2-what-is-a-chunk-LurUJ
- Chunking for learning software development : https://www.learncoderetain.com/chunking-for-learning-software-development/
- https://en.wikipedia.org/wiki/Chunking_(computing)
- Difference between Chunks and Buffer https://www.geeksforgeeks.org/what-is-the-difference-between-chunk-and-the-buffer-data/
- Chunk : https://www.devx.com/terms/chunk/
- Chunking (computing) https://en.wikipedia.org/wiki/Chunking_(computing)
- Chunked transfer encoding : https://en.wikipedia.org/wiki/Chunked_transfer_encoding
- Releasing "Chunk Scatter", an HTTP chunked encoding analysis tool : https://blog.yonatan.dev/chunk-scatter-http-chunked-response-analysis-tool
- How can I handle HTTP chunked transfer encoding in web scraping? https://webscraping.ai/faq/http/how-can-i-handle-http-chunked-transfer-encoding-in-web-scraping
- PHP
- https://github.com/symfony/symfony/tree/7.2/src/Symfony/Component/HttpClient/Chunk
- Streamed response in Symphony https://yarnaudov.com/symfony-streamedresponse-large-files-example.html
- A Comprehensive Guide to PHP's
array_chunk()Function : https://reintech.io/blog/comprehensive-guide-php-array-chunk-function - chunk_split : https://www.php.net/manual/fr/function.chunk-split.php
- Threaded::chunk : https://www.php.net/manual/fr/threaded.chunk.php
- Laravel Chunk : https://laravel-france.com/posts/optimisez-votre-application-avec-le-chunk-de-laravel
- Slides
- SymfonyLive Paris 2023: "Jongler en asynchrone avec Symfony HttpClient" : https://speakerdeck.com/alli83/jongler-en-asynchrone-avec-symfony-httpclient
- Streams : nous sous-estimons tous Predis ! https://afup.org/talks/4289-streams-nous-sous-estimons-tous-predis
- Flush your ! - an HTTP performance optimization tool - Reversim Summit '16 : https://speakerdeck.com/cowchimp/flush-your-an-http-performance-optimization-tool-reversim-summit-16?slide=15
- Chunking slides : https://fr.slideshare.net/slideshow/chunking-slides-62307461/62307461
- Chunking : https://fr.slideshare.net/slideshow/chunking-7706736/7706736
- DATA Chunk : https://fr.slideserve.com/marianne/data-chunk
- Youtube
- Lazy Collection - Pol DELLAIERA + Keynote de clôture - AFUP Day 2021 Lille/Rennes : https://www.youtube.com/watch?v=Kp47f8dtqoo
- Streams : Nous sous-estimons tous Predis ! - Alexandre DAUBOIS - Forum PHP 2023 : https://www.youtube.com/watch?v=84SmSYccpZY
- Related
- Data deduplication : https://en.wikipedia.org/wiki/Data_deduplication
- Content-Defined Chunking (CDC) like Rolling hash algorithm https://en.wikipedia.org/wiki/Rolling_hash
- Thunk : https://en.wikipedia.org/wiki/Thunk
- High Performance Browser Networking : http://chimera.labs.oreilly.com/books/1230000000545
matyo
$cacheBaseKey = "offers_{$gz}_{$iSiteId}_" . md5($query . '_' . $orderBy . '_' . implode(',', $categories) . '_' . implode(',', $brands) . '_' . $minPrice . '_' . $maxPrice);
matyo
matyo
/**
* cached offers are retrived by $cacheSize cached elements.
*/
private function getCachedOffers(
$gz,
$iSiteId,
$pageSize,
$numberPage,
$query,
$orderBy,
$categories,
$brands,
$minPrice,
$maxPrice,
) {
$cacheBaseKey = "offers_{$gz}_{$iSiteId}_" . md5($query . $orderBy);
$cacheSize = 1000;
$startIndex = $numberPage * $pageSize;
$endIndex = ($numberPage + 1) * $pageSize;
$startChunk = 0;
$endChunk = intval(floor($endIndex / $cacheSize));
$result = [];
$startPointerIndex = 0;
$endPointerIndex = 0;
for ($chunk = $startChunk; $chunk <= $endChunk; $chunk++) {
$chunkCacheKey = "cached_offers_{$cacheBaseKey}_chunk_{$chunk}";
if (!isset($_SESSION[$chunkCacheKey])) {
$fetchedData = GcpApiClient::getCatalogList(
$gz,
$iSiteId,
$cacheSize - 1,
$chunk,
$query,
$orderBy,
$categories,
$brands,
$minPrice,
$maxPrice,
);
$_SESSION[$chunkCacheKey] = $fetchedData;
}
$cachedChunk = $_SESSION[$chunkCacheKey];
$count = count($cachedChunk);
$endPointerIndex += $count;
if(($startPointerIndex <= $startIndex && $endPointerIndex >= $endIndex)
|| ($startPointerIndex >= $startIndex && $startPointerIndex <= $endIndex)
|| ($endPointerIndex >= $startIndex && $endPointerIndex <= $endIndex)) {
$result = array_merge($result, $cachedChunk);
} else {
$result = array_merge($result, array_fill(0, $count, null));
}
$startPointerIndex = $endPointerIndex;
}
$result = array_slice($result, $startIndex, $pageSize);
return $result;
}